文章目录[隐藏]
- 运行环境
- 实验步骤 (所有命令默认root用户执行)
- 1. 每台电脑上修改主机名
- 2. 查看每台设备IP后配置hostsname (hadoop1、hadoop2、hadoop3)
- 3.主机上生成ssh-rsa密钥
- 4. 分发前检查各节点ssh服务是否安装并开启
- 5. 检查每台设备是否允许root登录
- 6. 配置完成后使用 systemctl restart ssh 重启服务
- 7. 将主机密钥下发至其他节点
- 8. 在Windows创建共享文件夹,在linux使用SMB协议获取hadoop及java文件
- 9.在每个设备上创建/export/data,/export/servers,/export/software,授予/export读写权限。
- 10. 解压java、hadoop至/export/servers,修改文件夹名称,并配置系统环境
- 11. 检查配置情况
- 12. 配置完成后在主节点Hadoop目录中(/export/servers/hadoop/etc/hadoop)
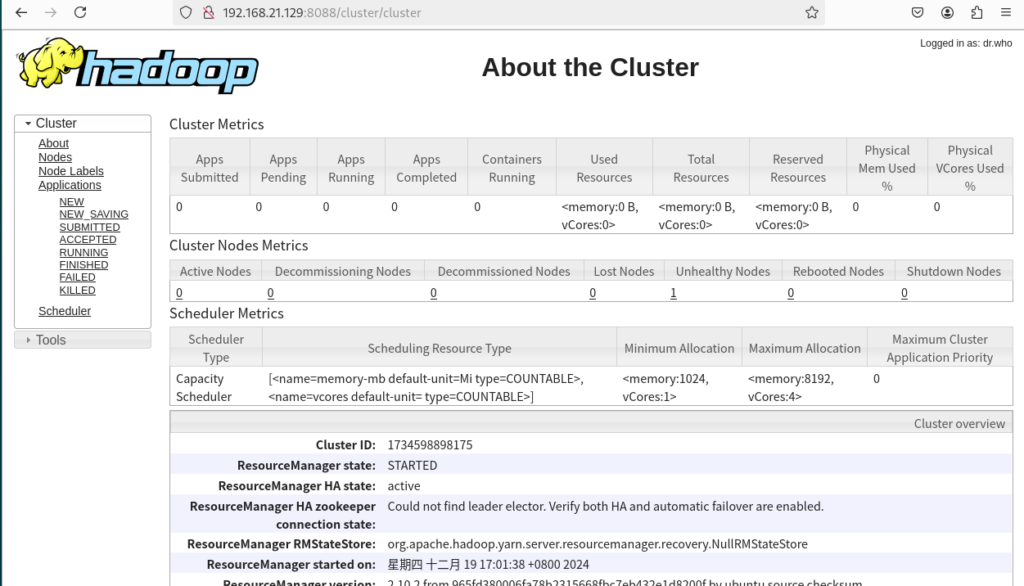
- 13. 打开浏览器通过IP查看各节点状态
- 14. 查看集群状态
本文参考:Hadoop集群安装和搭建(全面超详细的过程)_hadoop集群搭建-CSDN博客
运行环境
虚拟机宿主:VMware 17 in Windows 11
虚拟机系统:Debian 12 *3
前期配置:在虚拟机中完成系统的安装,设置网卡为VMnet8。完成后使用链接克隆三台。
实验步骤 (所有命令默认root用户执行)
1. 每台电脑上修改主机名
# 后面数字自己补
hostnamectl set-hostname hadoop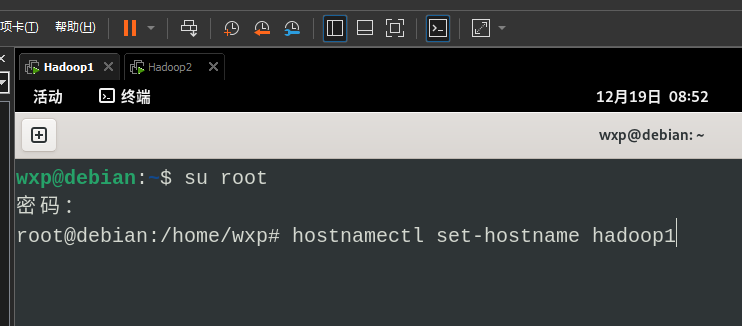
2. 查看每台设备IP后配置hostsname (hadoop1、hadoop2、hadoop3)
vim /etc/hosts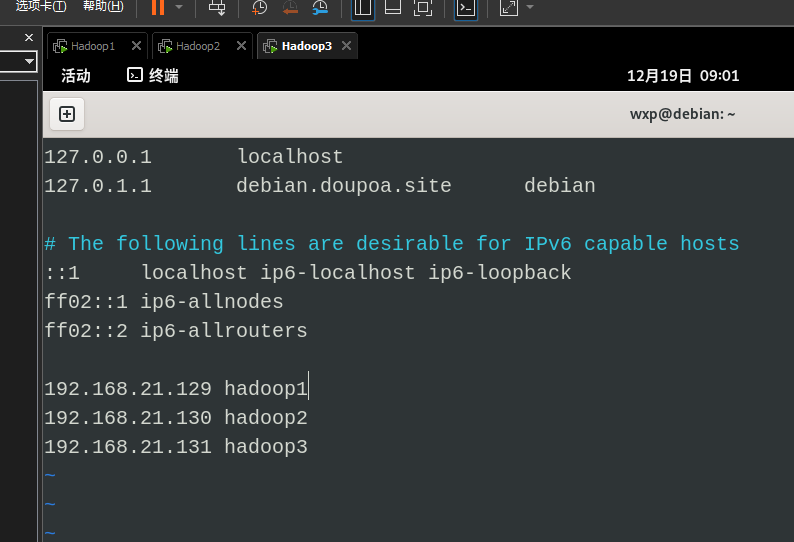
3.主机上生成ssh-rsa密钥
此处就已经需要ssh server了,如果提示 ssh 指令不存在,请执行安装。
# ssh指令不存在就运行这一行
apt install openssh-server
# 生成RSA密钥
ssh-keygen -t rsa
4. 分发前检查各节点ssh服务是否安装并开启
# 安装ssh服务器
apt install openssh-server
# 检查ssh状态
systemctl status ssh
# 启动ssh
systemctl start ssh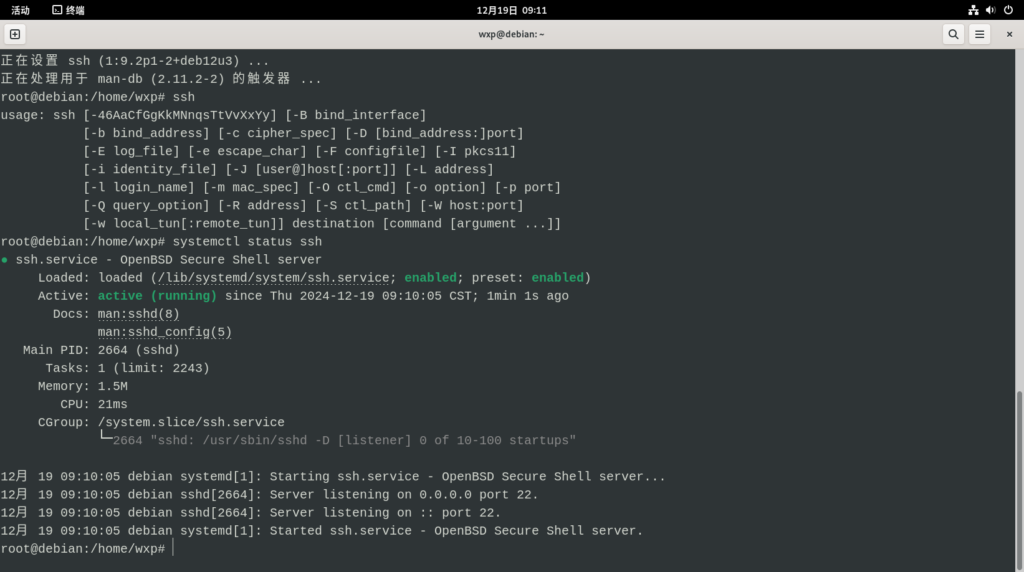
5. 检查每台设备是否允许root登录
注:PermitRootLogin prohibit-password 代表仅允许ssh密钥登录root。由于当前未完成密钥分发,此处先允许使用密码登录root
vim /etc/ssh/sshd_config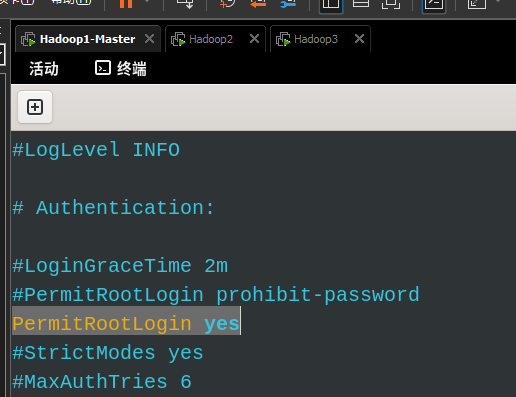
6. 配置完成后使用 systemctl restart ssh 重启服务
7. 将主机密钥下发至其他节点
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3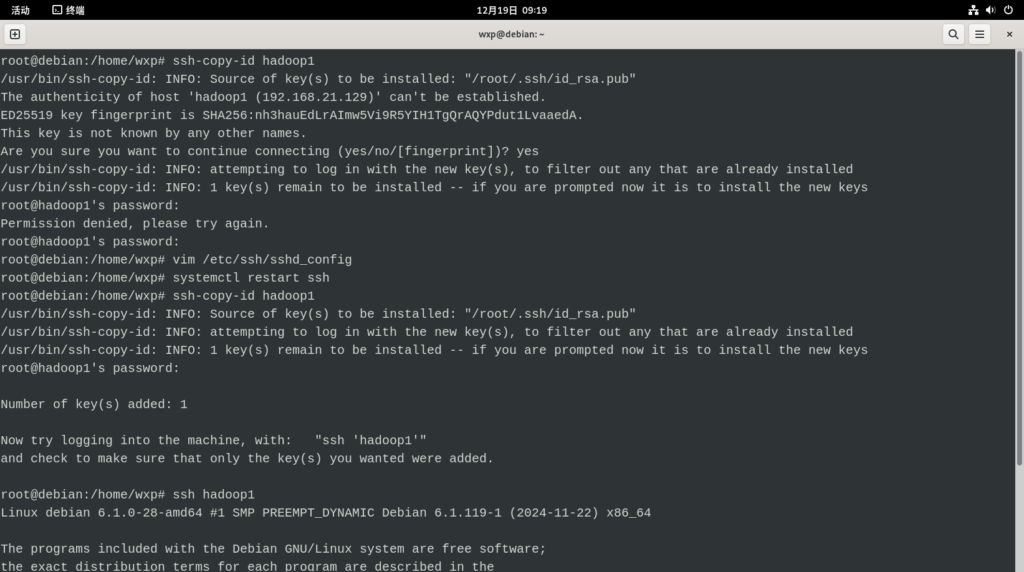
8. 在Windows创建共享文件夹,在linux使用SMB协议获取hadoop及java文件
此处随意,能把文件搞进虚拟机的方法就是好方法。VM虚拟机一般会有VMware Tools,但此处虚拟机安装后依然无法拖拽文件。
有关于配置共享文件夹的教程:传送门
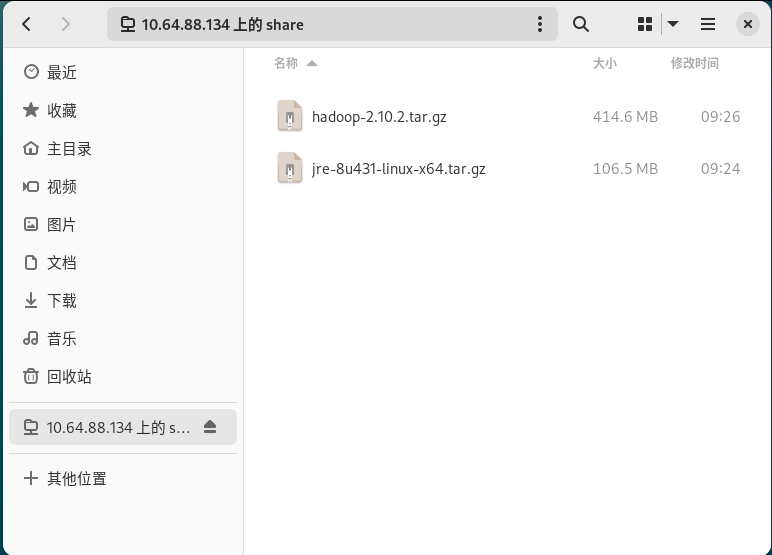
hadoop下载:传送门 (本文使用hadoop-2.10.2)
java下载:传送门 (java.com下载的是jre,缺少相关工具)
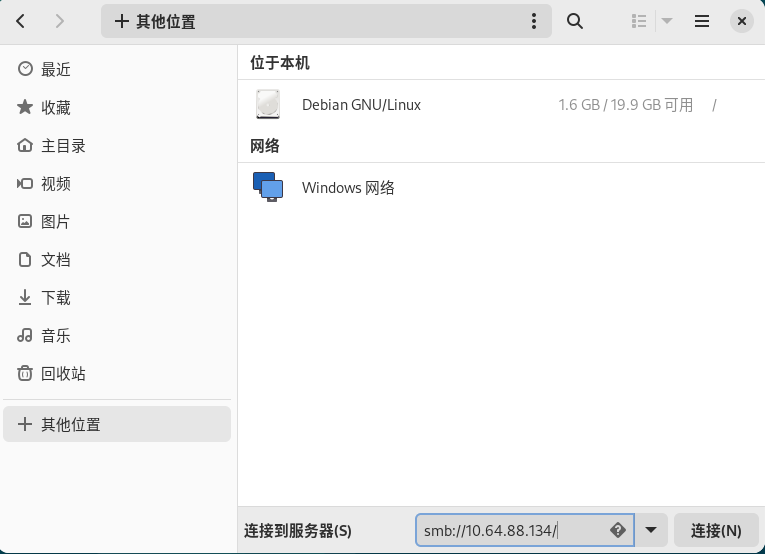
完成配置后如下访问文件夹:(smb://你Windows的IP/共享的文件夹名称)。即使开启免密也需要输入账号密码,我使用的是微软账号邮箱 + 微软账号密码,如果不行请另寻奇法。
9.在每个设备上创建/export/data,/export/servers,/export/software,授予/export读写权限。
mkdir /export
mkdir /export/data
mkdir /export/servers
mkdir /export/software
chmod -R 777 /export10. 解压java、hadoop至/export/servers,修改文件夹名称,并配置系统环境
此处配置在重新打开终端后会出现失效的问题,需要重新应用配置。相关解决方案:传送门
vim /etc/profile
# /etc/profile 文末中输入
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 完成配置后
source /etc/profile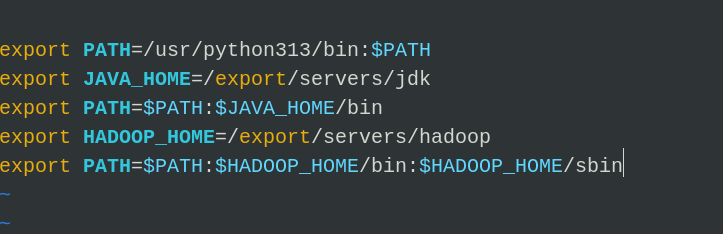
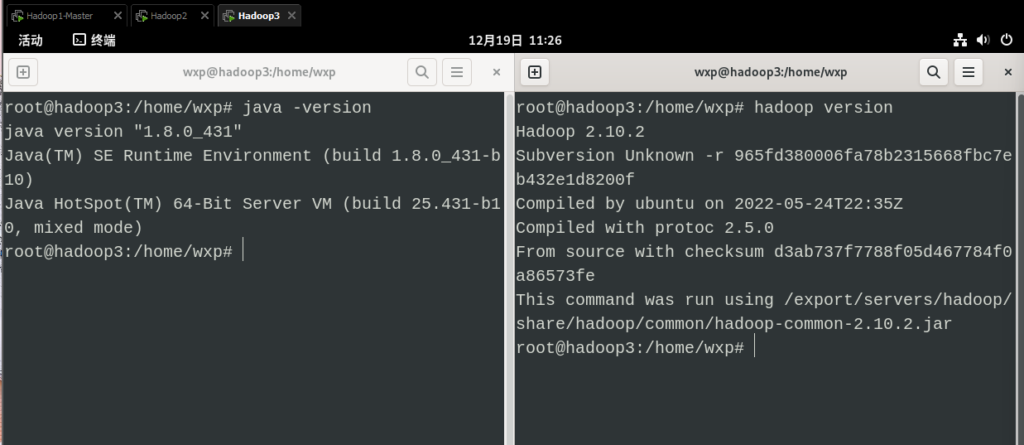
11. 检查配置情况
12. 配置完成后在主节点Hadoop目录中(/export/servers/hadoop/etc/hadoop)
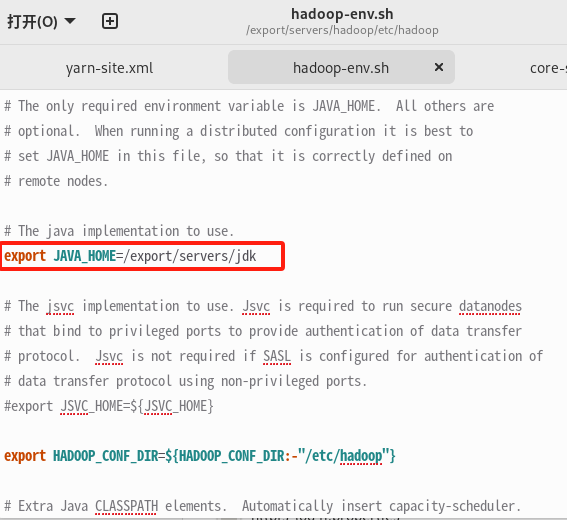
1. 修改 hadoop-env.sh 添加JAVA_HOME目录 (所有设备需操作)
如果在步骤10中解决了需要重复应用/etc/profile的问题,则本步骤可忽略
2. 修改 core-site.xml 修改configuration(所有设备需操作)

3. 修改 hdfs-site.xml 文件,添加节点

4. 修改 mapred-site.xml 文件,指定MapReduce运行时框架

5. 修改 yarn-site.xml 文件,指定集群管理者地址

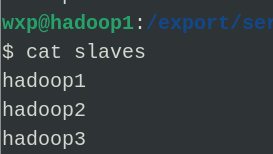
6.修改salves文件
7. 配置完成后在主机使用 hdfs namenode -format 格式化存储环境
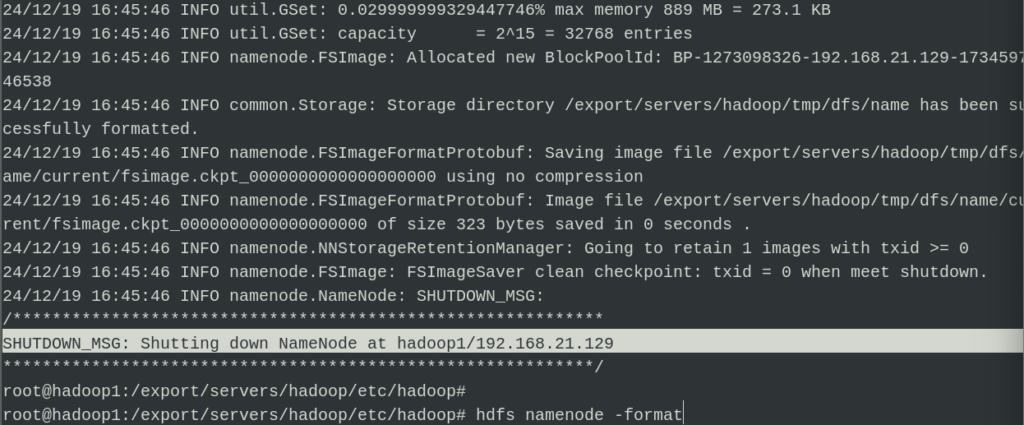
8. 分别在Root权限下使用start-dfs.sh 和 start-yarn.sh 启动节点
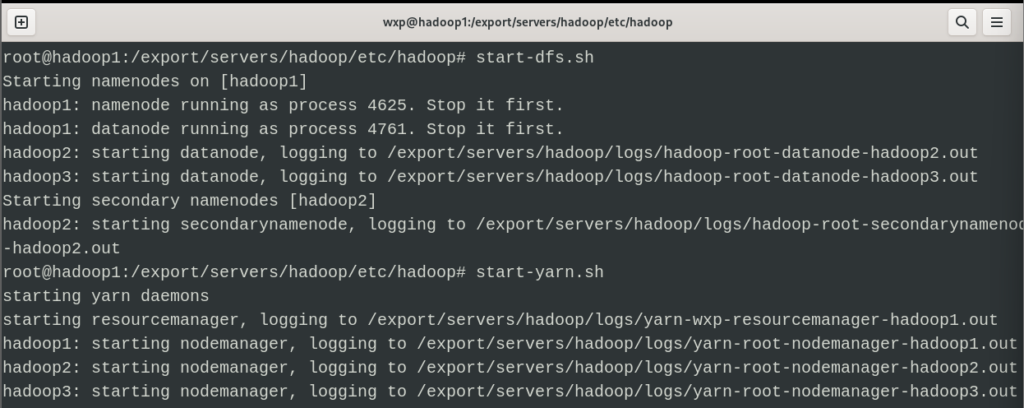
9. 使用jps查看节点 (本文使用jre8,无jps功能,暂不演示)
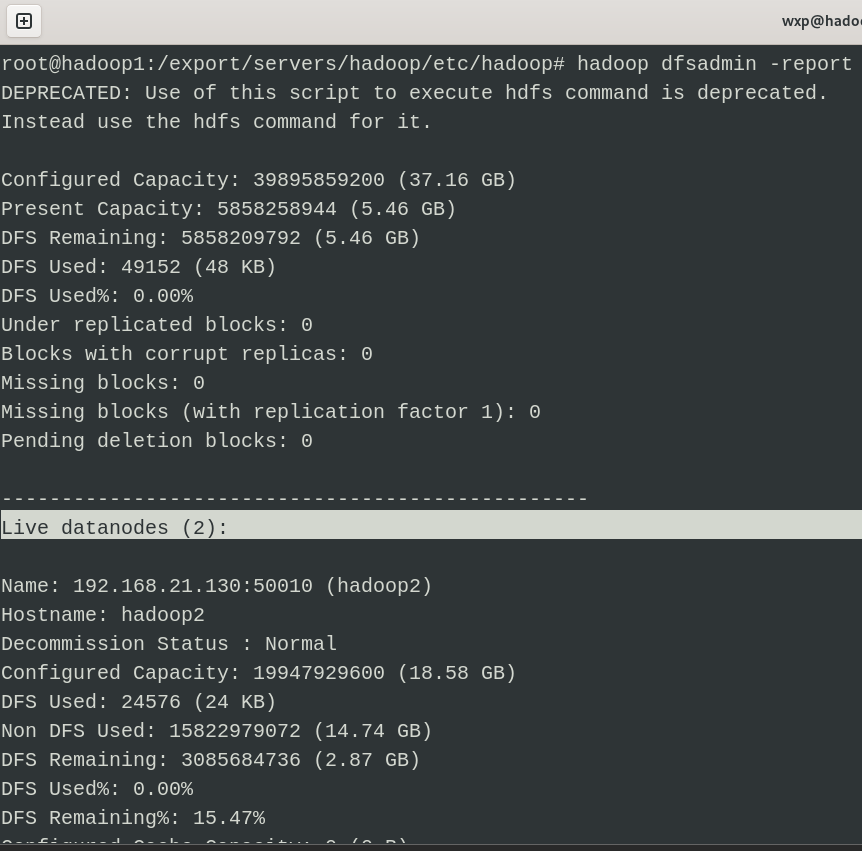
10. 使用 hadoop dfsadmin -report 查看节点状态
13. 打开浏览器通过IP查看各节点状态
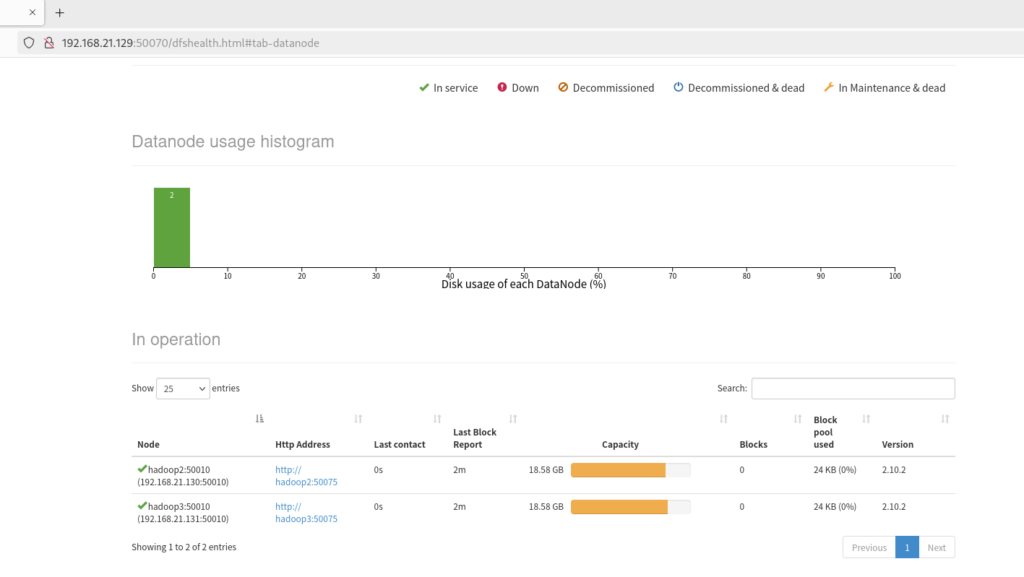
14. 查看集群状态

发表回复