
上一次实现了CosyVoice2的部署,这一次来讨论以下CosyVoice2如何保存音色。CosyVoice2音色保存
1.原理浅探
CosyVoice2当前版本(2025-01-10)很多周围工具都是1.0复用的,即使能用也会存在一点问题。当前CosyVoice2官方库不支持保存音色,连模型中spk2info也是复用1.0的。spk2info用于存放语音特征,每个说话人都有自己的音色特征,通过torch加载spk2info.pt可以看到其结构为{"说话人1":{'embedding':tensor(...), 'speech_token':tensor(...), 'speech_feat':tensor(...)}
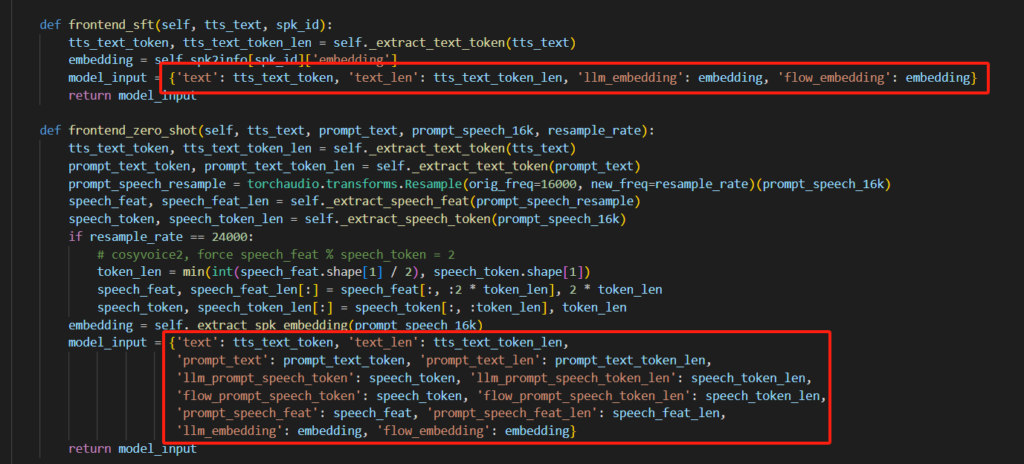
在最小化部署中,我们可以看到,每个功能都需要将我们设定的参考音频prompt_speech_16k传入到每个函数中。通过追踪prompt_speech_16k的去向,在cosyvoice库cli包下frontend.py模块里的frontend_zero_shot函数可以看到,我们的参考音频被处理为embedding、speech_token、speech_feat三个语音特征,随后通过model_input返回到上级。
具体处理逻辑实现过程请自行探究。
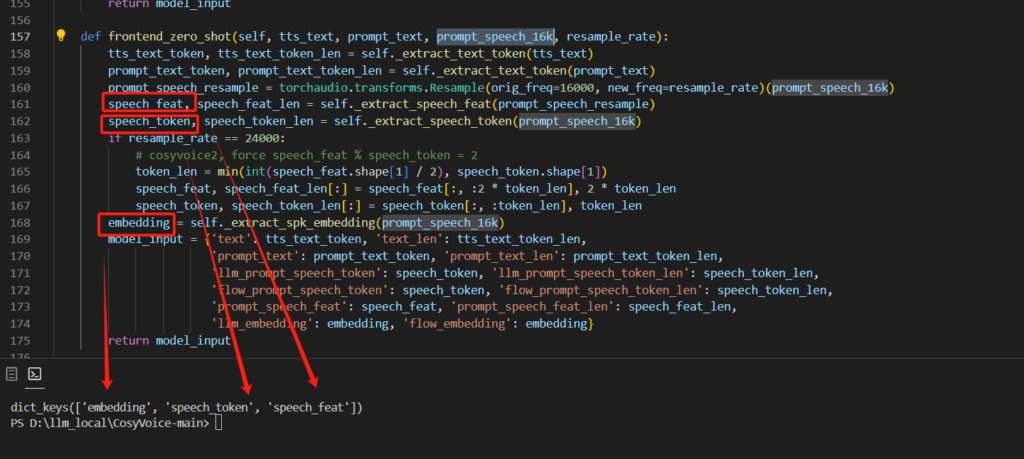
返回到调用上级,frontend_zero_shot的处理结果被传入了tts语音生成模块中,因此我们需要的语音特征其实就在最深层的frontend_zero_shot里,而原本的model_input则被tts模块覆盖成实际输出的音频块。
关于这一块的实现,就是将输入文本通过分割器对模仿人类在说话时的停顿进行切分,然后传入frontend_zero_shot中构建要处理的单词或字+音频特征的字典,以及后续使用预训练音频特征的实现原理也基本一致。但每一个字都要重新去获得音频特征,因此这一块可以考虑对其优化。
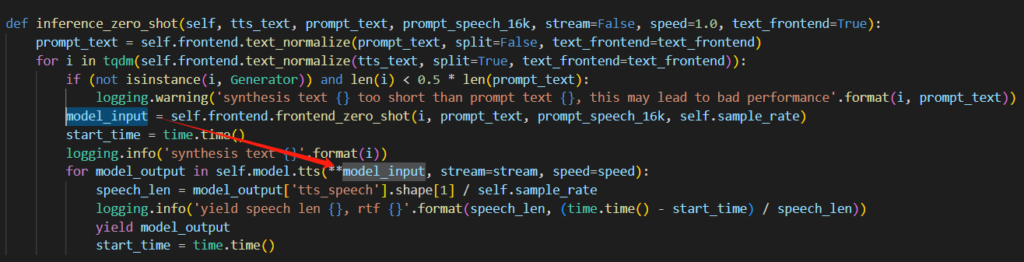
使用预训练音色这一块也是,传入说话人ID取出embedding音色特征,这下连speech_token、speech_feat这两个都用不到了。
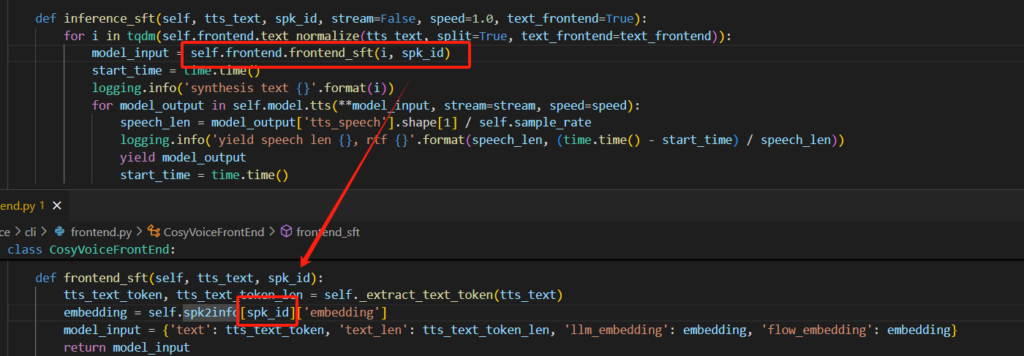
检查一下情感生成和指令生成的深层处理,都用到了frontend_zero_shot函数。
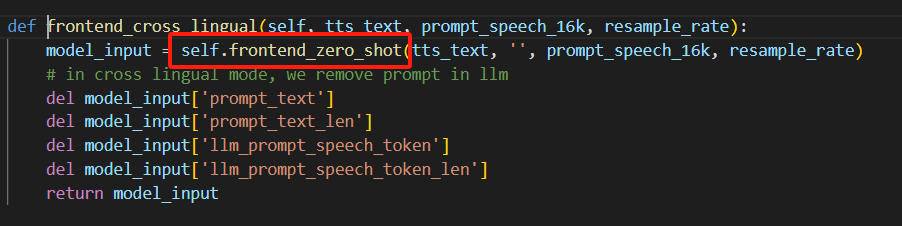

考虑当前需求实现的复杂性,我们可以直接将底层的frontend_zero_shot提取出来做一个单独的音色特征保存模块。
关于这部分的实现目的与需求,我认为在实际部署与生产中,大家都不希望自己的项目又大又复杂,模型需要使用的音色至多1-2个。既然我们能够通过上面的推理知道,音频生成其实只需要将音频特征和需要转换的文本传入tts模块中获取最终的处理结果,那我们是否能够在推理时直接传入我们需要的音频特征进行推理就可以了?
2.功能实现
根据以上推理结果,实现思路就直接将参考音频传入frontend_zero_shot获得音频特征,然后再通过对要生成语音的文本进行分词,最后传入sft中直接生成语音。以下代码展示的是最小化的音色提取、保存和普通生成:
import os
import sys
import time
import torch
import torchaudio
from tqdm import tqdm
from cosyvoice.cli.cosyvoice import CosyVoice2
from cosyvoice.utils.file_utils import load_wav
# 将第三方库Matcha-TTS的路径添加到系统路径中
sys.path.append('third_party/Matcha-TTS')
# 记录开始时间
start = time.time()
# 初始化CosyVoice2模型,指定预训练模型路径,不加载jit和trt模型,使用fp32
cosyvoice = CosyVoice2('pretrained_models/CosyVoice2-0.5B',
load_jit=False, load_trt=False, fp16=False)
# 设置最大音量
max_val = 0.8
# 设置说话人名称
speaker = '穗'
# 设置说话人信息文件的路径
spk2info_path = f'pretrained_models/CosyVoice2-0.5B/spk2info.pt'
# 设置提示文本
prompt_text = "我知道,那件事之后,良爷可能觉得有些事都是老天定的,人怎么做都没用,但我觉得不是这样的。"
# 设置要合成的文本列表
tts_text_list = ["收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。",
"人类不断挑战极限,在这一过程中超越自我,攀登新的高度。登山作为一项古老的极限运动,自古以来就吸引了无数冒险者,即使在现代,依然是许多人的热爱。"]
# 加载16kHz的提示语音
prompt_speech_16k = load_wav(f'{speaker}.wav', 16000)
# 如果说话人信息文件存在,则加载
if os.path.exists(spk2info_path):
spk2info = torch.load(
spk2info_path, map_location=cosyvoice.frontend.device)
else:
spk2info = {}
# 想要重新生成当前说话人音频特征的取消以下注释
#if speaker in spk2info:
# del spk2info[speaker]
if speaker not in spk2info:
# 获取音色embedding
embedding = cosyvoice.frontend._extract_spk_embedding(prompt_speech_16k)
# 获取语音特征
prompt_speech_resample = torchaudio.transforms.Resample(orig_freq=16000, new_freq=cosyvoice.sample_rate)(prompt_speech_16k)
speech_feat, speech_feat_len = cosyvoice.frontend._extract_speech_feat(prompt_speech_resample)
# 获取语音token
speech_token, speech_token_len = cosyvoice.frontend._extract_speech_token(prompt_speech_16k)
# 将音色embedding、语音特征和语音token保存到字典中
spk2info[speaker] = {'embedding': embedding,
'speech_feat': speech_feat, 'speech_token': speech_token}
# 保存音色embedding
torch.save(spk2info, spk2info_path)
print('Load time:', time.time()-start)
# 定义一个文本到语音的函数,参数包括文本内容、是否流式处理、语速和是否使用文本前端处理
def tts_sft(tts_text, speaker_info:dict,stream=False, speed=1.0, text_frontend=True):
'''
参数:
tts_text:要合成的文本
speaker:说话人音频特征
stream:是否流式处理
speed:语速
text_frontend:是否使用文本前端处理
返回值:
合成后的音频
'''
# 使用tqdm库来显示进度条,对文本进行标准化处理并分割
for i in tqdm(cosyvoice.frontend.text_normalize(tts_text, split=True, text_frontend=text_frontend)):
# 提取文本的token和长度
tts_text_token, tts_text_token_len = cosyvoice.frontend._extract_text_token(i)
# 提取提示文本的token和长度
prompt_text_token, prompt_text_token_len = cosyvoice.frontend._extract_text_token(prompt_text)
# 获取说话人的语音token长度,并转换为torch张量,移动到指定设备
speech_token_len = torch.tensor([speaker_info['speech_token'].shape[1]], dtype=torch.int32).to(cosyvoice.frontend.device)
# 获取说话人的语音特征长度,并转换为torch张量,移动到指定设备
speech_feat_len = torch.tensor([speaker_info['speech_feat'].shape[1]], dtype=torch.int32).to(cosyvoice.frontend.device)
# 构建模型输入字典,包括文本、文本长度、提示文本、提示文本长度、LLM提示语音token、LLM提示语音token长度、流提示语音token、流提示语音token长度、提示语音特征、提示语音特征长度、LLM嵌入和流嵌入
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
'prompt_text': prompt_text_token, 'prompt_text_len': prompt_text_token_len,
'llm_prompt_speech_token': speaker_info['speech_token'], 'llm_prompt_speech_token_len': speech_token_len,
'flow_prompt_speech_token':speaker_info['speech_token'], 'flow_prompt_speech_token_len': speech_token_len,
'prompt_speech_feat': speaker_info['speech_feat'], 'prompt_speech_feat_len': speech_feat_len,
'llm_embedding': speaker_info['embedding'], 'flow_embedding': speaker_info['embedding']}
# 使用模型进行文本到语音的转换,并迭代输出结果
for model_output in cosyvoice.model.tts(**model_input, stream=stream, speed=speed):
yield model_output
# 遍历文本列表
for text in tts_text_list:
# 记录开始时间
start = time.time()
# 遍历每个文本的生成结果
for i, j in enumerate(tts_sft(text, speaker=spk2info['穗'],stream=False, speed=1.0, text_frontend=True)):
# 保存生成的语音到文件,文件名包含文本的前四个字符
torchaudio.save('穗_{}.wav'.format(
text[0:4]), j['tts_speech'], cosyvoice.sample_rate)
# 打印处理时间
print('time:', time.time()-start)经测试,读取保存的音色跟正常调用实时处理的方式效果一致:
语音1:收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。
语音2:人类不断挑战极限,在这一过程中超越自我,攀登新的高度。登山作为一项古老的极限运动,自古以来就吸引了无数冒险者,即使在现代,依然是许多人的热爱。
另外在文中添加了对模型加载和音频生成的运行时间计时,本机设备配置:GTX1650+i7-10750H+512机械
模型加载耗时:约98秒
语音1:最终时长12秒,生成耗时20.59秒
语音2:最终时长17秒,生成耗时29.99秒
3.相关问题
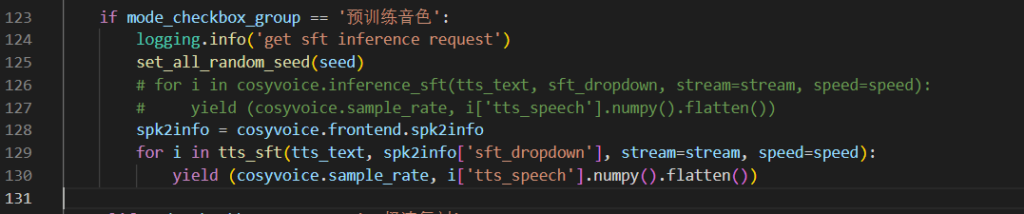
有些人可能会问,为什么在WebUI中使用这个音色生成的语音跟用代码生成的不一样?可以看到webui中使用的依然是CosyVoice1代的sft代码:

而1代向tts传入的参数跟2代传入的有很大区别,少传入了几个参数,会导致最终效果有很大区别
以下是相同文案使用1代CosyVoice(webui)推理的效果:
语音1:
语音2:
因此如果想要在WebUI中实现2代推理,我们只需要将cosyvoice.inference_sft换成我们自己实现的tts_sft就可以了。另外还需要取出音色的配置给tts_sft用,因此大致代码修改如下:

发表回复