文章目录
0.前言
这个问题主要是针对某个tx系产品做Playwright自动化时,网页样式和JS指向的CDN地址死活加载不出来。同样的该系列的其他网站也是因为CDN无法加载导致网站无法进入。多次测试后发现就是tx那边的CDN把我们的IP给封了。
那怎么办?IP被封业务还是要继续下去的。于是自己想了两个方案,一个是用云端服务器做代理,专门代理和缓存无法加载的CDN文件。但是这样就要经常去云端调整缓存方案,还要写一个服务端。实属有点麻烦,而且服务器那小水管…一个文件上传就把业务接口堵了
后来又想了个办法,既然不能从云端获取,那能不能做一个中间件判断加载慢的文件,在开发期间将所有加载慢的文件存到本地并稍微处理下?后面一试,嘿还真好用,平时转半天圈的网页直接秒开。
1.前期准备
我们需要整理一个需要代理的资源名单,因为目前连网站都进不去何谈访问。虽然后面已经实现了全自动的计时、缓存以及读取的流程,您也可以看看是我如何逐渐解决问题的。
以我的网站为例子,打开开发者工具,在网络选项卡中选中禁用缓存和慢速4G开关,以模拟在Playwright首次访问网站和网站加载过慢的情况。
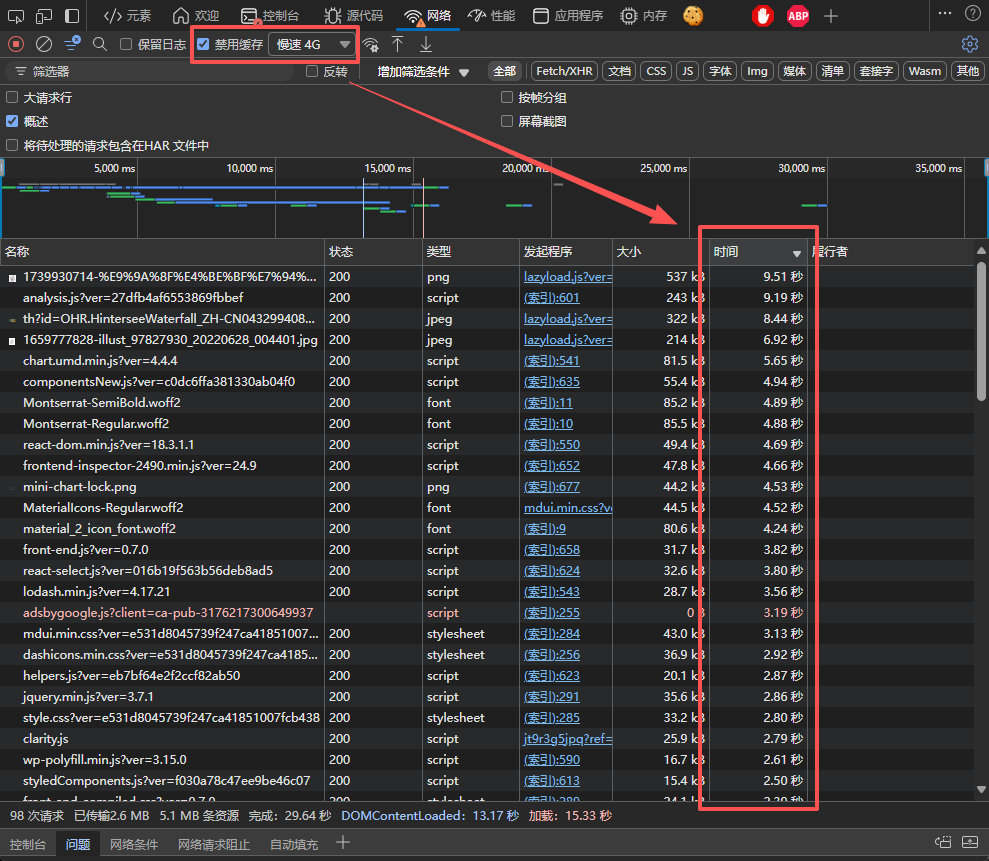
可以发现有很多资源加载超过1秒,网络日志记录器也为我们记录了所有资源的请求时长。那我们怎么保存这些数据?
在顶部有一个下载的按钮,我们可以将这些请求日志以HAR的形式保存下来
打开文件后可以看到这实际就是一个JSON文件,分为三个结构,log存储日志版本、创建者的相关信息,pages存储所访问网页的域名以及整体网站的加载时间。剩下的entries就是实际请求资源的基本信息。
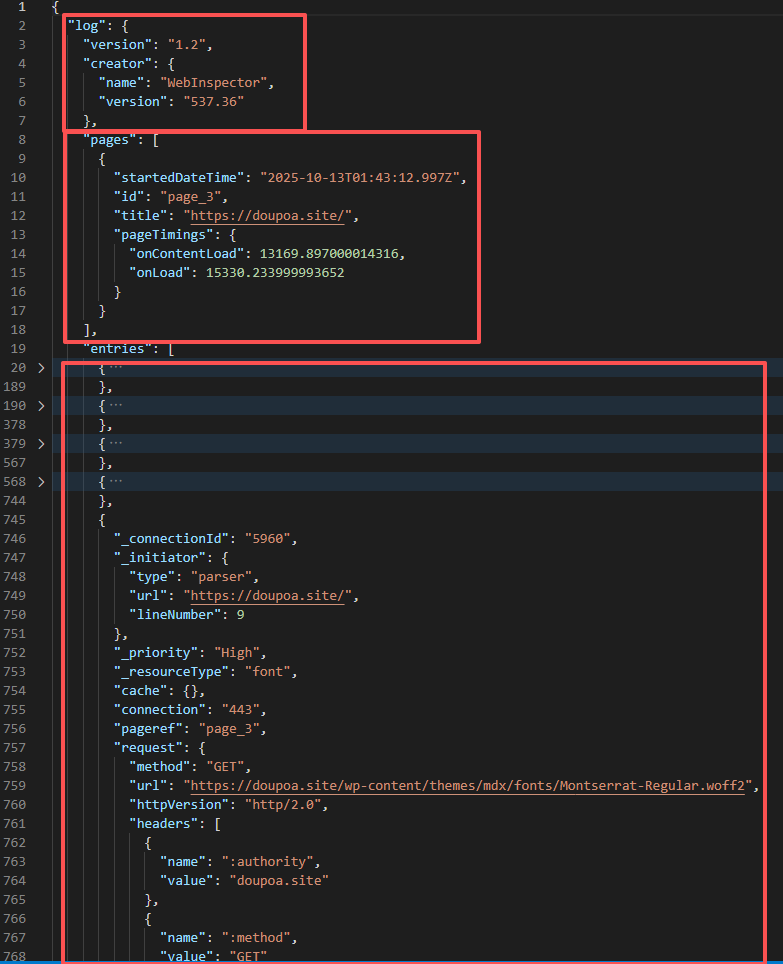
这样我们可以通过解析这个文件来提取加载时间大于1000毫秒的资源地址和文件名称,可通过以下脚本实现:
import json
# 手动执行工具类,用于处理从开发者工具捕获的日志文件
data = json.load(open("doupoa.site.har","r",encoding="utf-8"))
reports_list = []
reports_map = {}
for entries in data["log"]["entries"]:
filename = entries["request"]["url"].split("?")[0].split("/")[-1]
if entries["time"] < 1000 or filename.split(".")[-1] not in ["css","js","otf"]:
continue
reports_map[entries["request"]["url"]] = entries["request"]["url"].split("?")[0].split("/")[-1]
print(reports_map)
# 完成后手动复制粘贴至caching_route.py下载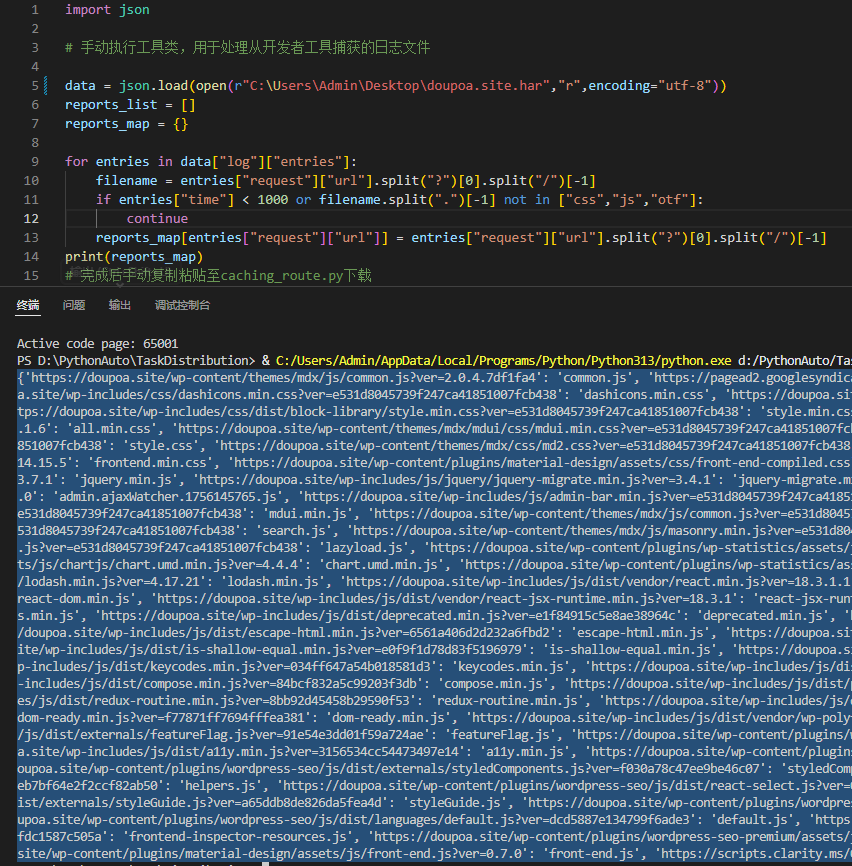
2.解决问题
我们获取要下载的资源后,之后就要看看怎么下载、保存以及加载。既然要缓存的资源要手动获取,那下载也只能靠手动运行。来看看整体代码:
import hashlib
import os
import re
from playwright.sync_api import Route, APIResponse
from playwright._impl._errors import TargetClosedError
from loguru import logger
import time
# 缓存被阻断的资源
class CachingRouteHandler:
def __init__(self, proxy_server):
self.proxy_server = proxy_server
self.cache_path = os.path.join(os.path.dirname(__file__), "cache")
os.makedirs(self.cache_path, exist_ok=True)
# 定义常见文件扩展名与MIME类型的映射
self.mime_types = {
'.js': 'application/javascript',
'.css': 'text/css',
'.png': 'image/png',
'.jpg': 'image/jpeg',
'.jpeg': 'image/jpeg',
'.gif': 'image/gif',
'.ico': 'image/x-icon',
'.svg': 'image/svg+xml',
'.woff': 'font/woff',
'.woff2': 'font/woff2',
'.ttf': 'font/ttf',
'.eot': 'application/vnd.ms-fontobject',
'.json': 'application/json',
'.html': 'text/html',
'.htm': 'text/html',
'.xml': 'application/xml',
'.txt': 'text/plain',
".wasm": "application/wasm"
}
def get_cache_path(self, url):
url_hash = hashlib.sha256(url.encode()).hexdigest()
return os.path.join(self.cache_path, f"{url_hash}.cache")
def get_mime_type(self, url):
"""根据URL获取MIME类型"""
# 移除查询参数
url_without_params = url.split('?')[0]
# 获取文件扩展名
_, ext = os.path.splitext(url_without_params)
# 返回对应的MIME类型,默认为application/octet-stream
return self.mime_types.get(ext.lower(), 'application/octet-stream')
def should_proxy(self, url):
"""判断是否需要走代理的规则"""
blocked_patterns = [
r'public\.gdtimg\.com',
r'qzonestyle\.gdtimg\.com',
r'ui\.tad\.woa\.com',
# 添加其他被阻断的域名模式
# r'\.js$', # 如果JS文件被阻断
# r'\.css$', # 如果CSS文件被阻断
]
for pattern in blocked_patterns:
if re.search(pattern, url):
return True
return False
def handle_route(self, route: Route):
request = route.request
url = request.url
if not self.should_proxy(url):
route.continue_()
return
cache_path = self.get_cache_path(url)
if os.path.exists(cache_path):
with open(cache_path, 'rb') as f:
body = f.read()
# 根据URL获取正确的MIME类型
mime_type = self.get_mime_type(url)
route.fulfill(status=200, body=body, headers={
"Content-Type": mime_type})
else:
# TODO 完善云端服务器代理接口逻辑
route.continue_()
return
# 否则通过代理获取资源
proxy_url = f"{self.proxy_server}/proxy/{url}"
logger.info(f"尝试通过代理获取资源: {proxy_url}")
response: APIResponse = route.fetch(url=proxy_url)
if response.ok:
body = response.body()
with open(cache_path, 'wb') as f:
f.write(body)
logger.info(f"缓存资源成功: {url}")
else:
logger.error(f"获取代理资源失败: {url}")
route.continue_()
if __name__ == "__main__":
# 转换已有的本地资源,放入cache下,自动转换为缓存格式文件
cache = CachingRouteHandler("127.0.0.1:8080")
resources_map = {...} # 刚刚提取的资源列表
import requests
for url, filename in resources_map.items():
file_path = os.path.join(cache.cache_path, filename)
hash_path = cache.get_cache_path(url)
# 直接改名
if os.path.exists(file_path):
print("正在处理:", filename)
os.rename(file_path, hash_path)
elif not os.path.exists(hash_path):
print("正在下载:", filename)
open(hash_path, 'wb').write(requests.get(url).content)
若直接运行代码,脚本就会遍历刚刚提取的资源列表,将所有资源下载并将资源地址通过sha256哈希化为文件名存储到指定缓存目录。
若Playwright需要使用可以通过以下方式,这样会让所有请求都会先过一遍缓存判断,相当于中间件。
from playwright.sync_api import sync_playwright
from caching_route import CachingRouteHandler
res_cache = CachingRouteHandler("http://127.0.0.1:8000")
with sync_playwright() as p:
browser = p.chromium
page = browser.new_page()
page.route("**/*", lambda route: res_cache.handle_route(route))
page.goto("https://doupoa.site")可以发现代码中有mime类型字典以及proxy_server参数,先说proxy_server,这个是前期设想的走云端代理的方式,但目前暂未实现,您可以自行实现或移除。而mime类型,在返回对应的缓存资源文件时,如果浏览器发现返回的文件与指定的mime类型不同就会拒绝加载。
3. 自动化检测及缓存
每次都要手动整理下载那些加载时间长的资源,那我们能不能将这一个过程自动化,在访问页面时自动计算每个资源的加载时间,超过阈值的资源将缓存?
class CachingRouteHandler:
...
class TimingCachingRouteHandler(CachingRouteHandler):
def __init__(self, proxy_server, timeout_threshold=2000):
super().__init__(proxy_server)
self.timeout_threshold = timeout_threshold # 超时阈值,单位毫秒
self.white_list = [
r'lp\.open\.weixin\.qq\.com',
r'open\.weixin\.qq\.com',
r'sso\.e\.qq\.com'
]
def handle_route(self, route):
request = route.request
url = request.url
if any(re.search(pattern, url) for pattern in self.white_list):
route.continue_()
return
# 检查是否已经有缓存
cache_path = self.get_cache_path(url)
if os.path.exists(cache_path):
with open(cache_path, 'rb') as f:
body = f.read()
mime_type = self.get_mime_type(url)
route.fulfill(status=200, body=body, headers={
"Content-Type": mime_type})
return
# 对于某些需要监控的资源,检测响应时间
if self.should_proxy(url):
# 记录开始时间
start_time = time.time()
try:
# 尝试获取响应
response = route.fetch()
# 计算响应时间
elapsed_time = (time.time() - start_time) * 1000 # 转换为毫秒
# logger.debug(f"请求 {url} 耗时: {elapsed_time:.2f} ms")
# 如果响应时间超过阈值,则缓存响应
if elapsed_time > self.timeout_threshold:
logger.info(f"请求 {url} 响应时间过长,已缓存")
body = response.body()
with open(cache_path, 'wb') as f:
f.write(body)
# 返回响应
response_body = response.body()
mime_type = self.get_mime_type(url)
route.fulfill(
status=response.status,
body=response_body,
headers={**response.headers, "Content-Type": mime_type}
)
return
except TargetClosedError:
route.continue_()
# logger.warning(f"浏览器已关闭,请求网页资源 {url} 失败")
except Exception as e:
logger.warning(f"从 {url} 获取网页资源因 {str(e)} 出错")
# 出错时继续正常流程
pass
# 默认情况下继续路由
route.continue_()
很简单,我们直接继承CachingRouteHandler,修改提供给Playwright的处理器handle_route,实现请求每个资源时对其计时,超过一段时间后将其自动缓存,下一次访问时读取缓存即可。
由于是检查整个访问的所有链接,有些本应展示的资源就会被拦截,例如登录二维码或者iframe内的元素。此时我们可以在 __init__中写入要忽略的域名,与这些域名匹配的所有资源将不会被缓存或代理。

发表回复