先上代码,主要功能就是下载视频字幕为ass并整理为txt格式。
关于Credential的填写:获取 Credential 类所需信息
Python
import asyncio
import os
import re
import pysubs2
from bilibili_api import Credential, ass, user, video
from loguru import logger
async def runner(bvid: str, c: Credential, play: int, title: str = ""):
logger.info(f"正在获取视频 {title} 字幕...")
v = video.Video(bvid=bvid)
try:
title = re.sub(r"[^\u4e00-\u9fa5]+", "", title)
await ass.make_ass_file_subtitle(v, page_index=0, out=f"{title}.ass", lan_code="ai-zh", credential=c)
except Exception as e:
logger.error(f"{title}: {e}")
return
# 提取ass字幕为纯文本
subtitle = pysubs2.load(f"{title}.ass")
with open(f"{title}.txt", "w", encoding="utf-8") as f:
for line in subtitle:
f.write(line.text + "\n")
f.write(f"-----\n播放量: {play}")
f.write(f"\n标题:{title}")
os.remove(f"{title}.ass")
async def main(uid: int, c: Credential):
video_list = []
u = user.User(uid, c)
page = 1
page_size = 30
total = 9999
while True:
logger.info(f"正在获取第{page*page_size}/{total}页视频数据")
videos = await u.get_videos(pn=page)
total = videos.get("page", {}).get("count", 9999)
for item in videos.get("list", {}).get("vlist", []):
video_list.append({"play": item.get("play", 0), "title": item.get(
"title", ""), "bvid": item.get("bvid", ""), })
if page * page_size >= total:
break
page += 1
logger.info(f"共获取{len(video_list)}个视频")
tasks = [runner(**item, c=c) for item in video_list]
await asyncio.gather(*tasks)
if __name__ == "__main__":
uid = 0
c = Credential(
sessdata="",
bili_jct="",
buvid3="",
dedeuserid="",
ac_time_value="")
asyncio.run(main(uid))
主要功能由bilibili-api实现,之前尝试过直接在页面内解析请求,只要能找到并点击打开字幕的JS方法,然后再捕获请求就行,找了半天虽然能定位到corePlayer的代码,但是没办法定位并操控实际函数。
后面也尝试过用RPA工具实现,但很麻烦也不想弄。于是就网上搜索发现有第三方的b站API接口,于是就尝试快速对接开发,终于能够实现功能。
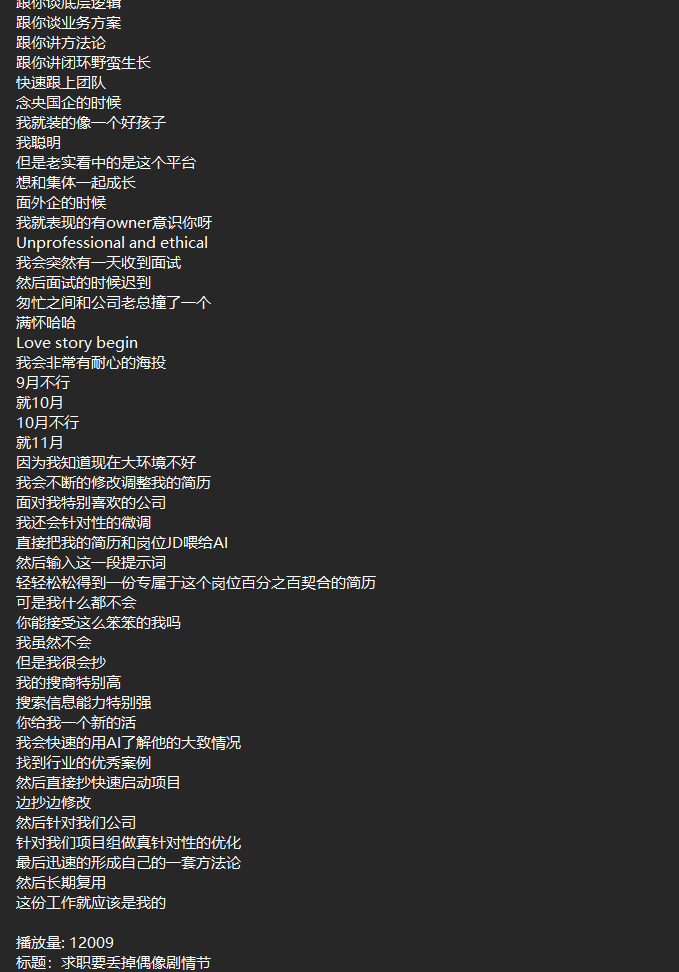
我这次爬的字幕为某个求职知识类UP主的视频字幕,他讲的内容有意义但非常碎片化。于是就产生导出字幕做成知识库的想法。最终脚本运行结果单个文件如下:
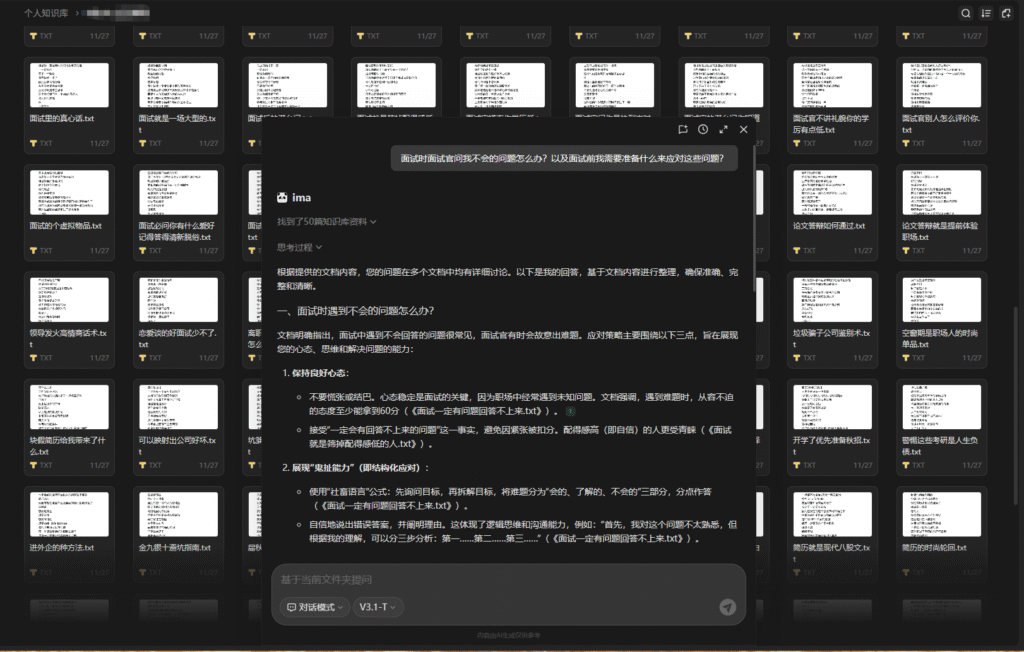
知识库的话也懒得搭建了,直接使用腾讯出品的ima知识库做整理,可以发现还是挺精准的
另外来个任务模式兑换码,用完删除

发表回复