文章目录[隐藏]
本文以 C语言程序设计基础 公开课为例,公开课与加入学习的课程爬取方式不太一样,但底层的请求逻辑是一样的。
个人爬虫开发思想: 在浏览器的原生Javascript环境中运行JS代码以实现数据抓取。与传统Python爬虫相比,能够基本跳过环境的逆向、还原时间。
1.原理浅析
点击进入课程,打开F12分析代码。
先看视频代码,可以看到视频源地址就写在src里。
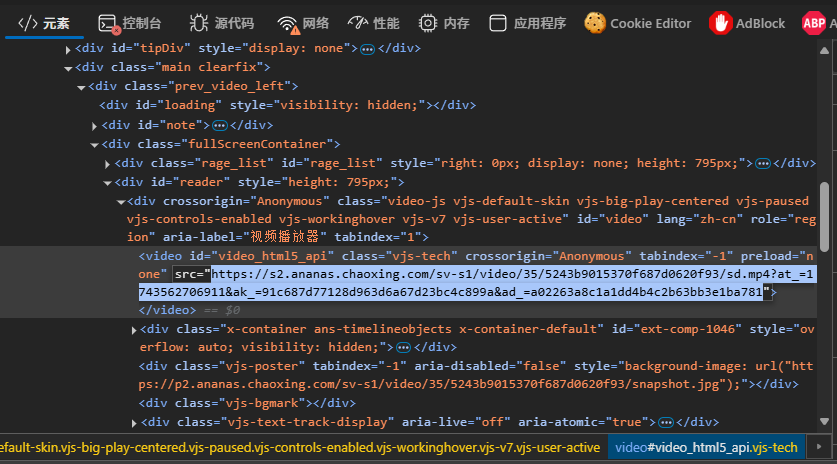
但如果我们直接访问这个地址就会提示403

往上查看可以看到视频是被包裹在iframes里的,这种反爬手段基于内外的环境检测。
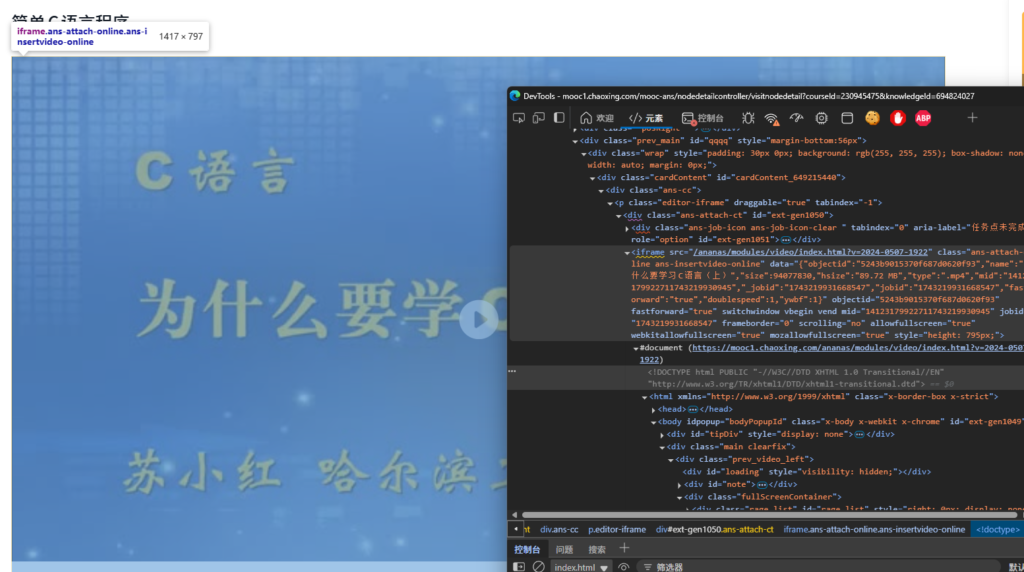
如果单独打开iframes,会因为无法获取原本iframes外部参数导致视频无法加载。而直接访问源视频,又会因检测到请求源地址不匹配从而被服务器拒绝访问。另外我们再尝试将请求成功的所有参数粘贴到apifox中请求,依然会提示403。
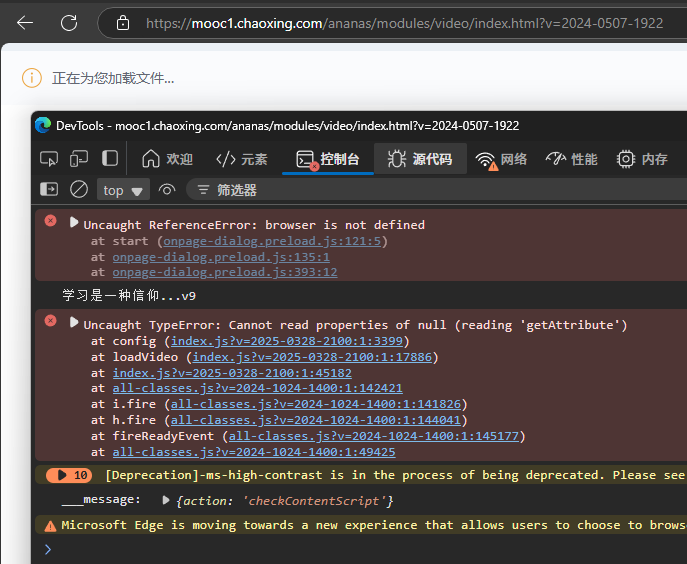
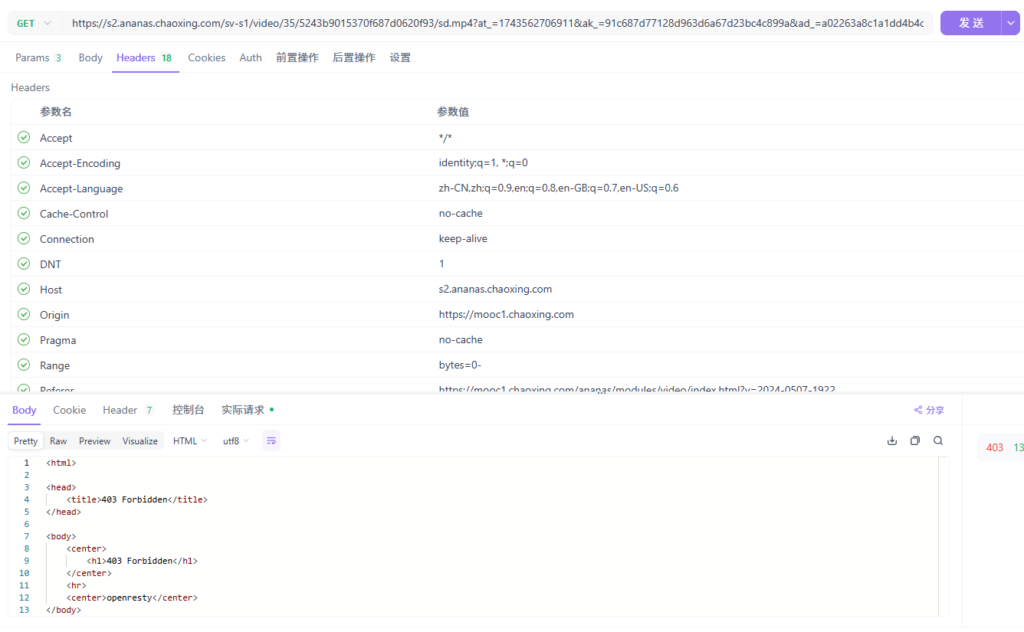
因此可以得出结论,我们必须要在完整的网页中通过iframes发送请求并捕获数据。相关原理可参考:对抗抖音X-Bogus、msToken新思路 < Ping通途说
另外我们再来看看点击“下一节”的跳转方式。
经实验得出,如果是无需登录的公开课,点击下一节课会重新访问新的课程地址(即会跳转,刷新整个页面)。而登录后点击账号内课程的下一课,则只会更新特定区域的课程内容(不会整页刷新)。整页刷新的坏处就是会打断脚本的运行,因此我们在写代码的时候需要考虑这一方面的问题。
2. 代码示例与解析
若需要避免运行脚本被打断,且又要跳转页面,那我们可以使用 var win = window.open 的方式获取对应窗口,之后就能够操作页面元素了。
再来看看怎么操作页面内的frame元素。可以通过以下方式获取当前窗口内iframes的源地址,这里是展示的是第一个frames。

之后再操作frames将视频地址创建为点击链接,通过fetch 方法获取视频的blob数据,最后保存成文件即可。这一块可以参考以下方式:
// 视频下载
const downloadPromise = fetch(videoUrl).then(res => res.blob()).then(blob => {
// 创建一个<a>元素用于下载
const a = win.document.createElement("a");
// 创建一个对象URL用于指向blob数据
const objectUrl = win.URL.createObjectURL(blob);
// 设置下载文件的名称
a.download = name;
// 设置<a>元素的href属性为对象URL
a.href = objectUrl;
// 模拟点击<a>元素以触发下载
a.click();
// 在控制台输出下载开始的信息
console.log("开始下载: " + name);
// 释放对象URL
win.URL.revokeObjectURL(objectUrl);
// 移除<a>元素
a.remove();
})完整示例代码
const POLL_INTERVAL = 2000;
const LOAD_TIMEOUT = 10000;
const CLOSE_DELAY = 5000; // 页面关闭前等待5秒
var cursor = document.getElementsByClassName("cursorC");
var urlQueue = [];
var isProcessing = false;
// 轮询检测窗口加载状态
function waitForWindowLoad(win) {
return new Promise((resolve, reject) => {
const startTime = Date.now();
const checkInterval = setInterval(() => {
if (Date.now() - startTime > LOAD_TIMEOUT) {
clearInterval(checkInterval);
reject(new Error("窗口加载超时"));
return;
}
try {
if (win.closed) {
clearInterval(checkInterval);
reject(new Error("用户手动关闭了窗口"));
} else if (win.document) {
// 增加双重验证:文档加载完成 + 关键元素存在
const isDocReady = win.document.readyState === "complete";
const hasTitle = win.document.querySelector(".prev_title");
const hasFrames = win.frames && win.frames.length > 0;
if (isDocReady && hasTitle && hasFrames) {
clearInterval(checkInterval);
resolve();
}
}
} catch (e) {
// 跨域异常忽略
}
}, POLL_INTERVAL);
});
}
async function Worker(url) {
var win = window.open("?" + url + "&mooc2=1", "");
try {
await waitForWindowLoad(win);
let hasVideos = false;
const downloadPromises = [];
// 遍历所有frames查找视频
// 遍历当前窗口中的所有iframe
for (var i = 0; i < win.frames.length; i++) {
try {
// 检查当前iframe是否包含video_html5_api对象
if (win.frames[i].video_html5_api) {
// 如果找到视频,设置hasVideos为true
hasVideos = true;
// 获取视频的URL
const videoUrl = win.frames[i].video_html5_api.src;
// 构造下载文件的名称,包括页面标题和iframe的序号(如果只有一个iframe则不添加序号)
const name =
win.document.getElementsByClassName("prev_title")[0].innerText +
(win.frames.length == 1 ? "" : " - " + (i + 1));
// 创建一个Promise来处理视频下载
const downloadPromise = fetch(videoUrl)
.then((res) => res.blob())
.then((blob) => {
// 创建一个<a>元素用于下载
const a = win.document.createElement("a");
// 创建一个对象URL用于指向blob数据
const objectUrl = win.URL.createObjectURL(blob);
// 设置下载文件的名称
a.download = name;
// 设置<a>元素的href属性为对象URL
a.href = objectUrl;
// 模拟点击<a>元素以触发下载
a.click();
// 在控制台输出下载开始的信息
console.log("开始下载: " + name);
// 返回一个新的Promise,用于在1秒后清理对象URL和<a>元素
return new Promise((resolve) => {
setTimeout(() => {
// 释放对象URL
win.URL.revokeObjectURL(objectUrl);
// 移除<a>元素
a.remove();
// 解析Promise
resolve();
}, 1000); // 增加清理延迟
});
});
// 将当前下载Promise添加到下载Promise数组中
downloadPromises.push(downloadPromise);
}
} catch (frameErr) {
// 捕获并输出处理视频时的错误信息
console.error("处理视频时出错:", frameErr);
}
}
if (!hasVideos) {
console.log("当前页面未找到视频");
win.close();
return;
}
// 等待所有下载完成
await Promise.all(downloadPromises);
} catch (err) {
console.error("下载过程中出错:", err);
} finally {
setTimeout(() => {
try {
win.close();
} catch (e) {}
}, CLOSE_DELAY);
}
}
// 重写链接处理函数
function linkUrlFunc(url) {
if (!urlQueue.includes(url)) {
urlQueue.push(url);
}
processQueue();
}
async function processQueue() {
if (urlQueue.length != cursor.length) {
return;
}
while (urlQueue.length > 0) {
const currentUrl = urlQueue.shift();
await Worker(currentUrl);
}
}
// 初始化处理
if (cursor && cursor.length > 0) {
console.log(`共发现 ${cursor.length} 节课`);
// 收集所有需要处理的URL
for (let i = 0; i < cursor.length; i++) {
// 创建临时函数触发原始点击事件来获取URL
cursor[i].click();
}
} else {
throw new Error("未找到课程,程序结束");
}将以上代码粘贴至开发者工具运行即可。
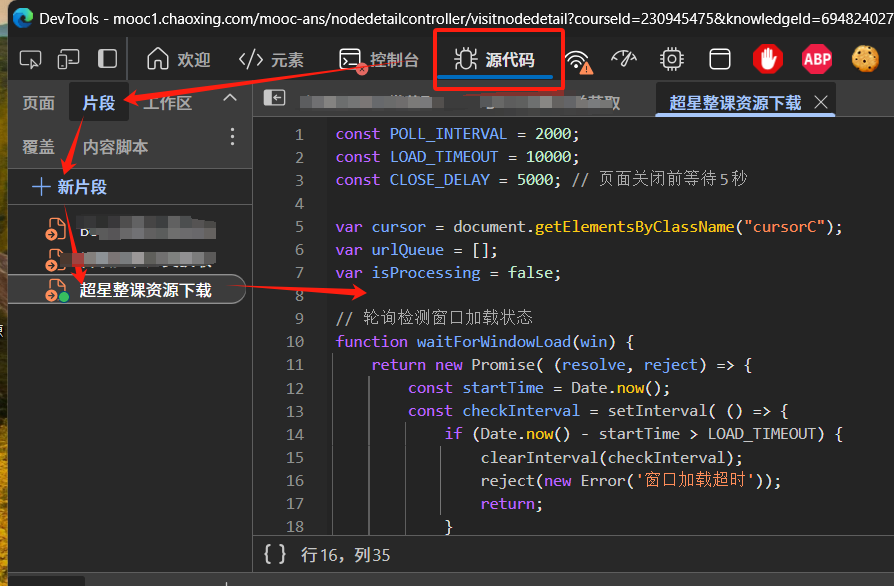
代码主要逻辑:首先通过点击课程章节来收集所有需要处理的URL,并将这些URL放入一个队列中。然后,它会依次处理队列中的每个URL,通过打开一个新的窗口来加载URL,并等待窗口加载完成。一旦窗口加载完成,它会查找窗口中的所有视频,并下载这些视频。下载完成后,它会关闭窗口,并继续处理队列中的下一个URL。整个过程是异步的,可以同时处理多个URL。

发表回复