0. 引言
最近是“数据预处理”课程的实践周。日常除了完成一些小作业外,还布置了一份 智能客服 大作业,要求如下:

学习过程中接触了 SnowNLP (一个中文处理库),可以自己准备数据集训练,用来进行情感识别。一开始我都打算使用这个库实现大作业了,后面听到老师说,“无论方法,只要实现功能即可”。那既然如此,可以直接接入LLM不更好?
在得知“任写”的消息之前,我已经使用 Albert 模型训练了一个情感分类器。但 “智能回复” 这方面暂时不知道怎么写(如果是通过识别后的情绪随机从语料库中选择一个,那也太无趣了)。
本文使用的数据集如下,来源 “老师”,如有侵权请联系删除。
1. Albert 情感分析器
老规矩先上代码
训练
# 使用alBert 模型进行情绪分析
import warnings
import pandas as pd
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import DataLoader, Dataset
from transformers import (AlbertForSequenceClassification, BertTokenizer,
DataCollatorWithPadding, Trainer, TrainingArguments)
warnings.filterwarnings("ignore")
## 1. 数据准备
# 读取数据
# 统一所有数据列为label和review
print("1. 读取数据")
# 读取第一个数据集
data1 = pd.read_csv("数据集/earphone_sentiment.csv",encoding="gbk")
# content_id,content,subject,sentiment_word,sentiment_value
# 0,Silent Angel期待您的光临,共赏美好的声音!,其他,好,1
# 2,这只HD650在1k的失真左声道是右声道的6倍左右,也超出官方规格参数范围(0.05%),看来是坏了,其他,,0
data1 = data1[["sentiment_value","content"]]
data1.columns = ["label","review"]
# 读取第二个数据集
data2 = pd.read_csv("数据集/hotle 7k+.csv",encoding="utf-8")
# label,review
# 1,"距离川沙公路较近,但是公交指示不对,如果是""蔡陆线""的话,会非常麻烦.建议用别的路线.房间较为简单."
# 1,商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!
# 读取第三个数据集
data3 = pd.read_csv("数据集/waimai_10k.csv",encoding="utf-8")
# label,review
# 1,很快,好吃,味道足,量大
# 1,没有送水没有送水没有送水
# 合并数据集
data = pd.concat([data2])
data = data.sample(frac=1).reset_index(drop=True) # 打乱数据集
print("2. 数据预处理")
# 数据预处理
data["review"] = data["review"].str.strip()
data["review"] = data["review"].str.replace("\n", "")
data["review"] = data["review"].str.replace("\t", "")
data = data.dropna()
data = data.drop_duplicates()
data = data.reindex(columns=["label", "review"])
data["label"] = data["label"].apply(lambda x: 2 if x == 1 else 0) # 1→2, 0→0
assert set(data["label"].unique()).issubset({0, 2})
print("3. 数据集划分")
# 数据集划分
train_data, test_data = train_test_split(data, test_size=0.3, random_state=42)
# 数据集划分
train_data, val_data = train_test_split(train_data, test_size=0.5, random_state=42)
print(" 训练集大小:", len(train_data))
print(" 验证集大小:", len(val_data))
print(" 测试集大小:", len(test_data))
print("4. 加载模型和分词器")
# 加载预训练的alBert模型
model = AlbertForSequenceClassification.from_pretrained("voidful/albert_chinese_small", num_labels=3,output_hidden_states=False)
# 数据集只有1和0,需要将负面(0)标签映射为0,正向标签(1)映射为2,中肯数据靠自学习识别为1
# 加载分词器
tokenizer = BertTokenizer.from_pretrained("voidful/albert_chinese_small")
class SentimentDataset(Dataset):
def __init__(self, data, tokenizer, max_length=256):
# 初始化数据集对象,传入数据、分词器和最大序列长度
self.data = data
self.reviews = data["review"].tolist() # 将评论数据转换为列表
self.labels = data["label"].tolist() # 将标签数据转换为列表
self.tokenizer = tokenizer # 保存分词器对象
self.max_length = max_length # 保存最大序列长度
def __len__(self):
# 返回数据集的长度
return len(self.data)
def __getitem__(self, idx):
# 根据索引获取单个数据项
text = str(self.reviews[idx]) # 获取评论文本
label = self.labels[idx] # 获取对应的标签
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True, # 添加特殊标记(如[CLS], [SEP])
max_length=self.max_length, # 设置最大序列长度
padding="max_length", # 使用最大长度进行填充
truncation=True, # 超出部分进行截断
return_attention_mask=True, # 返回注意力掩码
return_tensors="pt", # 返回PyTorch张量
)
return {
"input_ids": encoding["input_ids"].flatten(), # 平坦化输入ID张量
"attention_mask": encoding["attention_mask"].flatten(), # 平坦化注意力掩码张量
"labels": torch.tensor(label, dtype=torch.long), # 将标签转换为长整型张量
}
print("5. 数据加载")
# 创建数据集对象
train_dataset = SentimentDataset(train_data, tokenizer)
val_dataset = SentimentDataset(val_data, tokenizer)
test_dataset = SentimentDataset(test_data, tokenizer)
# 数据整理器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# 创建数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True,num_workers=4,collate_fn=data_collator)
val_dataloader = DataLoader(val_dataset, batch_size=16, shuffle=False,num_workers=4,collate_fn=data_collator)
test_dataloader = DataLoader(test_dataset, batch_size=16, shuffle=False,num_workers=4,collate_fn=data_collator)
# 训练模型
training_args = TrainingArguments(
output_dir="./results", # 输出目录
num_train_epochs=5, # 训练轮数
per_device_train_batch_size=16, # 每个设备的训练批次大小
save_strategy="epoch", # 保存策略,每个epoch保存一次
logging_dir='./logs', # 日志目录
)
trainer = Trainer(
model=model, # 训练的模型
args=training_args, # 训练参数
train_dataset=train_dataset, # 训练数据集
eval_dataset=val_dataset # 验证数据集
)
print("6. 开始训练")
trainer.train() # 开始训练
print("7. 保存模型")
# 保存模型
model.save_pretrained("albert_chinese_small_sentiment")
tokenizer.save_pretrained("albert_chinese_small_sentiment")推理
import torch
from transformers import AlbertForSequenceClassification, BertTokenizer
# 1. 加载已训练模型和分词器
model_path = "./albert_chinese_small_sentiment" # 训练保存的路径
model = AlbertForSequenceClassification.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained(model_path)
model.eval() # 切换到评估模式
# 2. 定义推理函数
def predict_sentiment(text, confidence_threshold=0.7):
"""
输入:
text - 待分析文本
confidence_threshold - 判定为中肯的最低置信度阈值
返回:
(pred_label, confidence, probabilities)
0=负面, 1=中肯, 2=正面
"""
# 文本编码
inputs = tokenizer(
text,
return_tensors="pt",
max_length=128,
padding=True,
truncation=True
)
# 模型预测
with torch.no_grad():
outputs = model(**inputs)
# 计算概率分布
probs = torch.nn.functional.softmax(outputs.logits, dim=-1)
top_prob, top_label = torch.max(probs, dim=1)
# 应用阈值判断中肯文本
if top_prob.item() < confidence_threshold:
return (1, top_prob.item(), probs.numpy()[0]) # 判定为中肯
return (top_label.item(), top_prob.item(), probs.numpy()[0])
# 3. 使用示例
text = "耳机用了一会就坏了,质量太差了吧"
label, confidence, probs = predict_sentiment(text)
print(f"文本: {text}")
print(f"预测: {['负面', '中肯', '正面'][label]}")
print(f"置信度: {confidence:.2f}")
print(f"概率分布: 负面={probs[0]:.2f}, 中肯={probs[1]:.2f}, 正面={probs[2]:.2f}")讲解
NLP模型训练与推理的主要流程其实就是:
- 加载数据集
- 处理数据集
- 切分数据集
- 定义数据集加载器
- 模型训练、测试与保存
- 模型推理
模型训练中,原始的数据集只有0(负面)和1(正面),但作业要求需要识别 “中肯” 的情感。因此在这一方面需要将 正面的1映射为2,中肯的判断就只能靠机器自学习。
映射完成后不要忘记在 AlbertForSequenceClassification.from_pretrained 中将 num_labels 设定为3,即代表数据 有3个类别。
在数据集构建方面,主要还是通过 继承Dataset 自定义 SentimentDataset,将数据集逐个切割、分词、添加SEP(代表句子末位)CLS(代表句子首位)等标志,最后转换为张量。(概念理解:标量、向量、矩阵、张量之间的区别和联系_标量 向量-CSDN博客)。通过 SentimentDataset 处理后的数据集对象,还需要 DataCollatorWithPadding 对 所有数据动态填充至相同长度。
最后调整训练参数传入训练数据集和测试数据集直接开始训练即可。
关于模型推理,加载训练好的模型和与模型一致的分词器,将要处理的文本传入分词器处理后交给模型预测推理,最后根据预设的阈值输出最终结果。本文使用的albert_chinese_small模型,在模型介绍页面作者特地说明了分词器必须使用BertTokenizer加载。
再看看推理代码中自定义的推理函数,先是将文本通过tokenizer向量化,转换为token张量序列,随后传入模型预测。模型预测结果有一项 logits,logits通常指的是网络最后一层的输出,一般需要传入 Sigmoid 函数或 Softmax函数进行处理。
Sigmoid函数 将 logits 映射到0,1的范围,用于表示每个独立事件的概率。
Softmax函数 将 logits 归一化为概率分布,输出的每个值表示该类别的相对概率,总和为 1。
这里我们想要得到三个情绪的概率,因此选择使用 Softmax 函数处理logits。另外可以发现,softmax和max函数都有一个dim参数,这个参数用于指定在哪个维度上进行操作,一般根据模型的张量结构来确定维度的深度。对于这段代码使用的Albert模型,其输出的outputs是一个包含多个元素的元组,其中outputs.logits是我们最关心的部分,它包含了模型对每个类别的预测分数(logits)。这个logits张量的维度通常是这样的:
num_classes:模型预测的类别数量。batch_size:一次输入模型的样本数量。
另外在大多数序列分类任务中,模型的输出 logits 结构如albert的张量结构一致,即 [batch_size, num_classes]。因此在这一段中,对softmax设置dim=-1,会在每个样本的类别概率维度(即最后一个维度)中找到最大概率的类别。对max设置dim=1,则会在类别维度上找到每个样本的最大概率类别及其概率值。
关于dim的更多描述可参阅:
Python-维度dim的定义及其理解使用_python dim-CSDN博客
Python - Dim=-1 或 -2 在 torch.sum() 中是什么意思?- 堆栈溢出
最后关于中肯的判断,如果概率最大的类别的概率值小于设定的置信度阈值,则判定为中肯。
测试
负面:耳机用一会就坏了,质量太差了吧
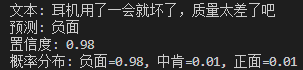
中肯:你好,这个怎么卖?
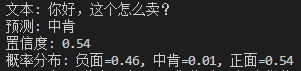
正面:质量不错,服务态度也很好,下次还会再来。
由于数据集倾向于1和0,显然想要让模型推测出中肯的概率会很低。因此只能依靠置信度阈值来辅助判断中肯了,阈值需要根据实际情况来调整。
2. 基于LLM的智能客服情绪分析系统
谈论
咱先捋一下设计思路,调用大模型谁都会,更多的还有一键安装部署的脚本或软件。
根据需求,我们需要实现一个能结合历史对话分析客户当前情绪。如果检测到用户存在负面情绪(如太差、难吃、投诉)等,大模型会介入生成应对方案,此外能够实现语音情绪识别就更好了。
参考之前我们实现的LLama-cpp-python在Windows下启用GPU推理 ,我们可以直接基于试用代码扩展我们的功能。关于语音情绪识别的需求,我们不可能在3天时间内搓出能够深入通过分析音频波形来判断情绪的模型,因此可以直接用语音识别文本(ASR)的方式传给大模型判断。
一开始尝试过Whisper、DeepSpeech这类ASR大模型,但资源消耗实在是太高了(对于我的电脑来说),并且还有一定延迟,对于客服这种实时类任务可能不太适合。转念一想,手机输入法的语音识别是怎么实现的?在大模型诞生之前语音识别这块已经非常成熟了。
经过查阅资料后,传统离线语音识别模型是基于隐马尔可夫模型(HMM)、高斯混合模型(GMM)或浅层神经网络,依赖人工设计的声学特征(如MFCC)和语言模型,模型结构相对简单,计算资源需求低,适合嵌入式设备。在实际应用中一般只支持单一语言的语音转文字,识别准确率受限于模型规模和数据量,在嘈杂环境或口音差异较大的情况下性能下降明显。
而ASR大模型采用端到端深度学习架构(如Transformer、RNN-T),直接从语音信号映射到文本,无需人工特征工程。模型规模更大(参数数量达数亿至数十亿),依赖大规模数据训练,能够自动学习语音与文本的复杂映射关系。支持多语言、多任务(如语音翻译、语种识别),具备更强的鲁棒性和泛化能力。
在当前这个项目中,传统离线语音识别模型的低延迟和实时性特点比ASR大模型更好一点,经过最终选型,Vosk非常适合我们这个项目。Vosk分为两种模型,一种是可以用于嵌入式或轻量设备的单机离线模型,另一种就是适用于服务器部署的大型模型。
部署
语言大模型这方面选择 qwen2.5-3b,对于文本语义分类这种轻量任务非常适合,并且也能够理解问题并给出自然语言的应答回复。Vosk经过测试还是使用服务器版本的模型效果更好。
接下来就是给各种情况写提示词了:
请严格根据以下规则判断输入句子的情绪: 1. 负面情绪(如愤怒、失望)→输出"负面"或"非常负面" 2. 正面情绪(如高兴、满意)→输出"正面"或"非常正面" 3. 无明显情绪→输出"中性" 注意: - 只输出一个结果词(非常负面/负面/中性/正面/非常正面),不要添加任何解释 - 中性询问(如"这个商品怎么卖")应判断为"中性" - 示例: 输入:我讨厌这个产品! 输出:负面
请严格按以下规则分析对话情绪: 1. 对话中出现负面词汇(如"问题""投诉""生气")→"负面"或"非常负面" 2. 对话中出现正面词汇(如"感谢""满意""很棒")→"正面"或"非常正面" 3. 纯事务性对话(如询问、确认信息)→"中性" 要求: - 仅输出一个结果词(非常负面/负面/中性/正面/非常正面),不要添加任何解释 - 以最后一条用户发言的情绪为主 - 示例: 输入:客户:手机坏了!客服:请提供订单号 输出:负面
任务:为不满客户提供3条应答方案 规则: 1. 每条方案必须包含: - 共情表达(如"理解您的感受") - 具体行动承诺(如"24小时内处理") - 不超过100字 2. 格式:["方案1","方案2","方案3"] 3. 禁止添加解释或额外文本 示例: 输入:客户:收到破损商品! 输出:["非常抱歉给您带来不便,我们将优先处理您的订单,2小时内给您答复
任务:根据用户的问题生成回答 规则: 1. 回答必须包含: - 具体回答(如"我们提供7天无理由退货") - 不超过100字 2. 格式:["方案1","方案2","方案3"] 3. 禁止添加解释或额外文本 示例: 输入:客户:退货需要多久? 输出:["我们提供7天无理由退货,请您放心购买", "退货流程:1. 申请退货 2. 确认收货 3. 退款到原支付方式", "退货时间:收到商品后7天内"]
之后就是一些关于最大历史记录、token统计功能的完善。
另外,我还设定了用户输入的格式,必须用 客户|{客户输入} 客服|{客服输入} 的格式输入对话,也可以使用指令 “/建议 [问题]” 对问题生成回答。
让我们来看看效果:
# 客户|你好,这个商品怎么卖?
# 客服|你好,这个商品是100元,需要购买请告诉我。
# 客户|你们家商品质量太差了!我要投诉!
# 客服|很抱歉给您带来不便,请问您遇到了什么问题呢?

再来测试语音识别的功能,语音我是通过剪映文本生成的语音。输入语音需要添加 voice: 标签标识当前未语音文件。如:客户|voice:数据集/正面.wav
【正面】位置不错,在市中心.周围吃饭等很方便.房间一如既往的干净
【负面】服务质量不好,四星级的酒店,连矿泉水都没有,还得自己出钱买!

可以看出文本都能正确识别,情绪判断也正确。
最后展示一下整体文件代码:
from llama_cpp import Llama
import json
from vosk import KaldiRecognizer, Model,SetLogLevel
import os
from pydub import AudioSegment
# 本代码将用于辅助真人客服判断用户情绪,在检测到用户可能存在负面情绪时提醒客服,并给出应答方案。
SetLogLevel(-1) # 关闭vosk日志
chat_model_path = "D:\\llm_local\\qwen2.5-3b-instruct-q4_k_m.gguf"
vosk_model_path = "vosk-model-cn-0.22"
max_tokens = 1024
# 检查对话是否包含负面情绪的提示词
check_negative_emotion = """
请严格根据以下规则判断输入句子的情绪:
1. 负面情绪(如愤怒、失望)→输出"负面"或"非常负面"
2. 正面情绪(如高兴、满意)→输出"正面"或"非常正面"
3. 无明显情绪→输出"中性"
注意:
- 只输出一个结果词(非常负面/负面/中性/正面/非常正面),不要添加任何解释
- 中性询问(如"这个商品怎么卖")应判断为"中性"
- 示例:
输入:我讨厌这个产品!
输出:负面
"""
# 总结对话内容的提示词
summarize_conversation = """
请严格按以下规则分析对话情绪:
1. 对话中出现负面词汇(如"问题""投诉""生气")→"负面"或"非常负面"
2. 对话中出现正面词汇(如"感谢""满意""很棒")→"正面"或"非常正面"
3. 纯事务性对话(如询问、确认信息)→"中性"
要求:
- 仅输出一个结果词(非常负面/负面/中性/正面/非常正面),不要添加任何解释
- 以最后一条用户发言的情绪为主
- 示例:
输入:客户:手机坏了!客服:请提供订单号
输出:负面
"""
# 检测负面情绪时辅助客服回复的提示词
remind_customer_service = """
任务:为不满客户提供3条应答方案
规则:
1. 每条方案必须包含:
- 共情表达(如"理解您的感受")
- 具体行动承诺(如"24小时内处理")
- 不超过100字
2. 格式:["方案1","方案2","方案3"]
3. 禁止添加解释或额外文本
示例:
输入:客户:收到破损商品!
输出:["非常抱歉给您带来不便,我们将优先处理您的订单,2小时内给您答复","已记录您的问题,我们的质检团队将立即核查并补偿损失","为表歉意,我们将赠送您一张优惠券,稍后通过短信发送"]"""
# 对用户的问题生成回答的提示词
generate_response = """
任务:根据用户的问题生成回答
规则:
1. 回答必须包含:
- 具体回答(如"我们提供7天无理由退货")
- 不超过100字
2. 格式:["方案1","方案2","方案3"]
3. 禁止添加解释或额外文本
示例:
输入:客户:退货需要多久?
输出:["我们提供7天无理由退货,请您放心购买", "退货流程:1. 申请退货 2. 确认收货 3. 退款到原支付方式", "退货时间:收到商品后7天内"]
"""
class ChatSession:
def __init__(self):
self.vosk = Model(vosk_model_path,lang="zh")
self.rec = KaldiRecognizer(self.vosk, 16000)
self.llm = Llama(model_path=chat_model_path, max_tokens=max_tokens,
n_gpu_layers=-1, verbose=False, n_ctx=6144)
self.count_tokens = 0 # 当前对话占用的token数量
self.messages = [] # 历史对话
def get_response(self, content: str, method: str) -> tuple:
prompt = {"check_negative_emotion": check_negative_emotion, "summarize_conversation": summarize_conversation,
"remind_customer_service": remind_customer_service,"generate_response": generate_response}.get(method)
if self.messages:
prompt = prompt + "\n历史对话:\n" + \
",".join([i["content"] for i in self.messages])
response = self.llm.create_chat_completion(
[{"role": "system", "content": prompt}, {"role": "user", "content": content}])
self.add_message("客户:"+content)
# print("\n\n"+prompt+"\n"+content+"\n")
# print("\n"+response["choices"][0]["message"]["content"]+"\n\n")
return (response["choices"][0]["message"]["content"], response["usage"]["total_tokens"])
def get_voice_content(self,voice_path:str) -> str: # 将语音转为文字
# 读取语音
try:
audio = AudioSegment.from_file(voice_path)
audio = audio.set_channels(1).set_frame_rate(16000).set_sample_width(2) # 转为单声道,16kHz采样率,16位采样深度
wf = audio.raw_data
except:
return ""
# 识别语音
self.rec.AcceptWaveform(wf)
result = self.rec.FinalResult()
result = json.loads(result)
return result["text"]
# result = json.loads(self.rec.Result())
# if result["text"] == "":
# return self.rec.PartialResult()
# return result["text"]
def add_message(self, content: str):
message_tokens = len(self.llm.tokenize(content.encode("utf-8"), False))
self.messages.append({"content": content, "tokens": message_tokens})
self.count_tokens += message_tokens
if self.count_tokens > max_tokens:
# print(self.count_tokens, max_tokens)
tmp_messages = []
while self.count_tokens > max_tokens:
self.count_tokens -= self.messages[0]["tokens"]
tmp_messages.append(self.messages.pop(0))
content, tokens = self.get_response(
"\n".join([m["content"] for m in tmp_messages]), "summarize_conversation")
content = f"在历史对话中,用户情绪为:{content}"
tokens = len(self.llm.tokenize(content.encode("utf-8"), False))
self.messages.insert(0, {"content": content, "tokens": tokens})
self.count_tokens += tokens
print("环境初始化中..")
chat_session = ChatSession()
os.system("cls")
print("环境初始化完成,请输入对话,输入exit、stop或quit退出程序")
while True:
try:
user_input = input() # 用 客户|{客户输入} 客服|{客服输入} 的格式输入对话
print('\033[1A', end='') # 光标向上移动一行
print(" "*100, end="\r", flush=True) # 清除当前行内容
except KeyboardInterrupt:
break
if user_input in ["exit", "stop", "quit"]:
break
# 使用指令 “/建议 [问题]” 对问题生成回答
if user_input.startswith("/建议"):
content = user_input[3:]
response, tokens = chat_session.get_response(
content, "generate_response")
try:
text = json.loads(response)
response = " ".join(
[f"{i+1}. {text[i]}" for i in range(len(text))])
except:
pass # 解析失败则原样输出
print("\33[35m[ 回复方案 ]\33[0m", response)
continue
inputs = user_input.split("|")
if inputs[0] == "客户":
content = inputs[1]
if content.startswith("voice:"):
file_path = content[6:]
content = chat_session.get_voice_content(file_path)
if content == "":
print("\33[31m[ 警告 ] 语音识别失败,请重新输入\33[0m")
continue
response, tokens = chat_session.get_response(
content, "check_negative_emotion")
color = {"负面": "\33[31m", "正面": "\33[32m","非常负面": "\33[31m", "非常正面": "\33[32m",
"中性": "\33[34m", "无法判断": "\33[35m"}
print("\33[33m[ 客户 ]\33[0m",
f" {content} [{color.get(response, '\33[0m')}{response}\33[0m]")
if response in ["负面", "非常负面"]:
print("\33[31m[ 警告 ] 客户可能存在负面情绪,请客服注意\33[0m")
response, tokens = chat_session.get_response(
content, "remind_customer_service")
try:
text = json.loads(response)
response = " ".join(
[f"{i+1}. {text[i]}" for i in range(len(text))])
except:
pass # 解析失败则原样输出
print("\33[35m[ 回复方案 ]\33[0m", response)
elif inputs[0] == "客服":
content = inputs[1]
chat_session.add_message("客服:"+content) # 客服输入不判断情绪,直接添加到历史对话中
print("\33[36m[ 客服 ]\33[0m", content)
else:
print("输入格式错误,请使用 客户|{客户输入} 客服|{客服输入} 的格式输入对话")
# 客户|你好,这个商品怎么卖?
# 客服|你好,这个商品是100元,需要购买请告诉我。
# 客户|你们家商品质量太差了!我要投诉!
# 客服|很抱歉给您带来不便,请问您遇到了什么问题呢?
# 客户|voice:数据集/正面.wav
# 实际文本:位置不错,在市中心.周围吃饭等很方便.房间一如既往的干净
# 客户|voice:数据集/负面.wav
# 实际文本:服务质量不好,四星级的酒店,连矿泉水都没有,还得自己出钱买!
发表回复