0. 引言
Fun-CosyVoice3-0.5B在2025年12月16号开源,发布当天我就注意到了,只不过有事拖到了现在。一起来看看CosyVoice3.0效果与2.0相比新增和优化了哪些令人兴奋的功能!
可以发现模型名称由Cosyvoice2 -> Fun-Cosyvoice3,那是因为Cosyvoice3名称已经被商用版本优先占用了,先前的两个版本是直接开源的。(暂时无法判定当前发布的cv3就是商业版本)
Fun-Cosyvoice3从此处后称Cosyvoice3
而仔细观察模型发行者可以发现,Cosyvoice1和2都是由“通义实验室”发行,而Fun-CosyVoice3则由“通义百聆”发行,即FunAudioLLM。
虽然在魔搭社区中不同版本由不同组织发行,但是在Github和HuggingFace中则都是FunAudioLLM管。
因此先前想要“生万物”的通义实验室,也是终于将不同种类的模型拆分成各个专精组织,由通义实验室统一管理。

以上内容均为个人猜测,与官方无关。
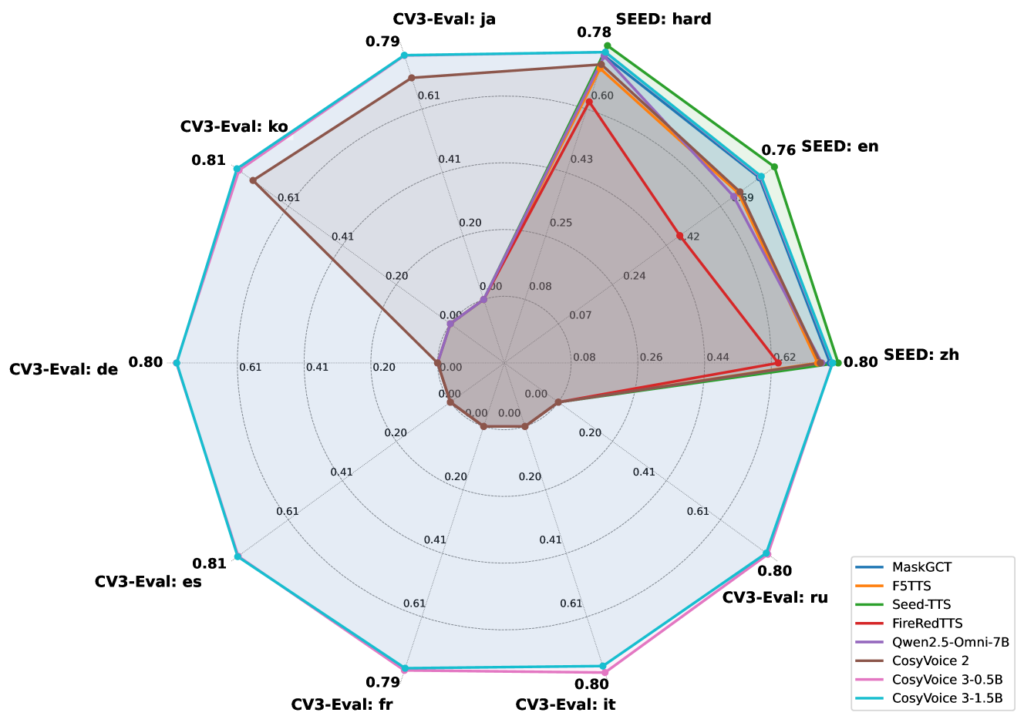
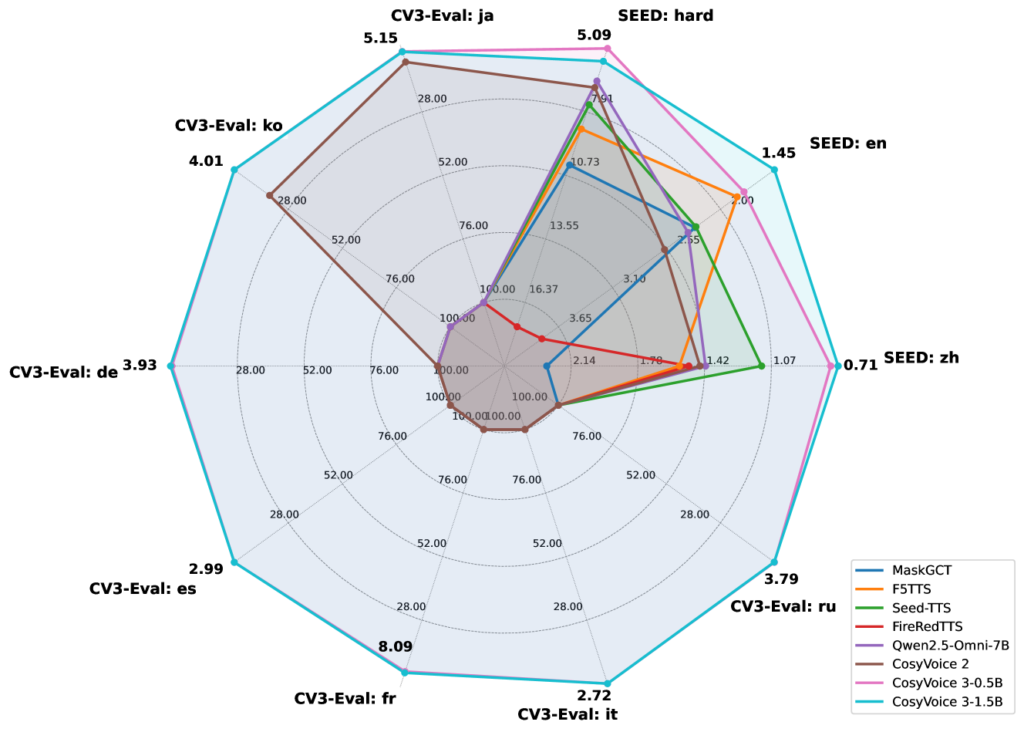
根据查阅Cosyvoice3的论文可以发现:cosyvoice3在多种语言上全面吊打cosyvoice2,在中文上0.5B与1.5B内容一致性(即想要实现的效果与实际实现的效果对比)相近,英文上1.5B更胜一筹,其他语言几乎一致。
说话者相似性就是输出的音频与原声相似度,这一块0.5B和1.5B打成平手,且处于市场上各模型顶尖位(在论文发布时)。
因此对于普通用户常用的中文情景,0.5B在性价比上更佳。
关于Cosyvoice2的部署与应用可参考:
CosyVoice2-0.5B在Windows下本地完全部署、最小化部署 < Ping通途说
1. 环境搭建
Cosyvoice3的环境与Cosyvoice2一模一样,依然需要从Github克隆仓库,创建Conda环境并初始化,此处不再重复阐述,请查阅CosyVoice2-0.5B在Windows下本地完全部署、最小化部署 1-3节,以及5.1小节。
另外说一下,conda环境默认创建在C盘,如果想要创建在其他盘中,例如E盘,可通过以下方式:
conda create -y python=3.10 -p e:/conda/envs/cosyvoice-env创建完成后就需要通过conda activate e:/conda/envs/cosyvoice-env 来激活环境。
如果不想要前面的e:/conda/envs/又或是环境位置过深,可以执行conda config --add envs_dirs e:/conda/envs/,添加环境目录到conda中。
此时可以通过conda info --envs验证环境和conda activate cosyvoice-env以激活环境。
以及PyTorch下载慢的问题,由于限定了Python版本(3.10)和PyTorch版本(2.3.1),该版本的CUDA最多支持到CU121,所以可以直接通过点击下方链接下载Windows平台的PyTorch和PyAudio。
https://mirrors.aliyun.com/pytorch-wheels/cu121/torch-2.3.1+cu121-cp310-cp310-win_amd64.whl
https://mirrors.aliyun.com/pytorch-wheels/cu121/torchaudio-2.3.1+cu121-cp310-cp310-win_amd64.whl
下载完成后在对应conda环境中执行 pip install xxx.whl 即可。
2. 启动项目
待一切就绪后,我们打开从github上克隆下来的推理项目,打开webui.py可以发现已经指定了cosyvoice3目录。
其中--model_dir可以指定本地模型和在modelscope中的repo id。如果此时还没有下载模型,可以将default值修改为FunAudioLLM/Fun-CosyVoice3-0.5B-2512,运行时会自动从魔搭中下载。
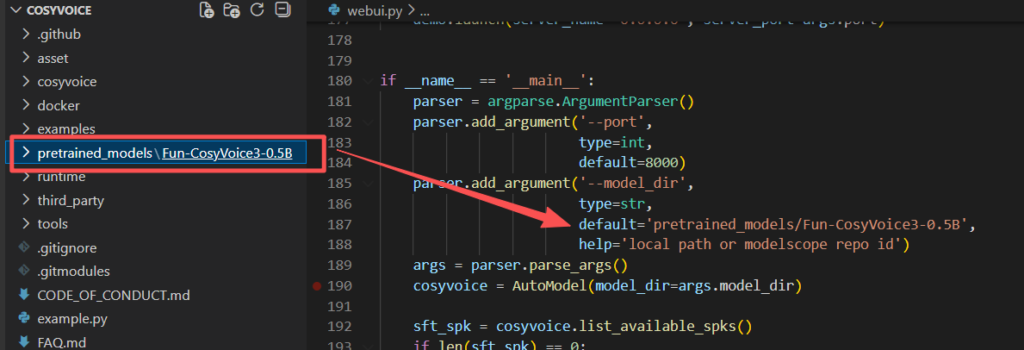
另外启动时还可能遇到DLL初始化失败的问题,根据gradio 与 kaldifst 冲突 · Issue #1553 · FunAudioLLM/CosyVoice,问题是因为库引用顺序导致的
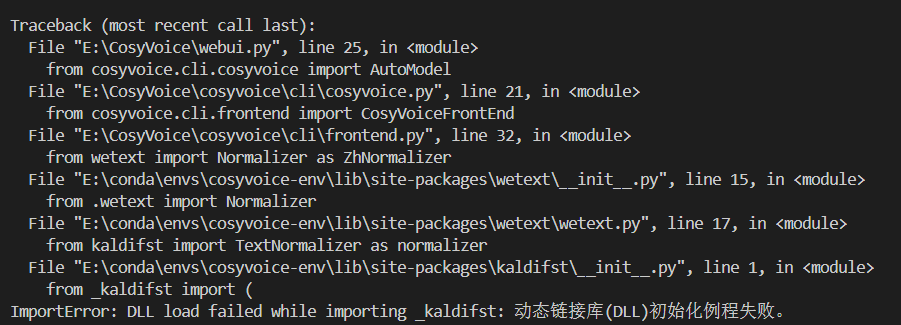
请替换import为以下几行后重新启动(即Cosyvoice库先加载)
from cosyvoice.utils.file_utils import logging
from cosyvoice.utils.common import set_all_random_seed
from cosyvoice.cli.cosyvoice import AutoModel
import argparse
import os
import random
import sys
import gradio as gr
import numpy as np
import torchaudio若一切顺利,脚本会开始初始化并下载wetext相关依赖,直到刷屏结束时检查输出是否存在http://localhost:8000/,那么此时就可以打开网址进入webui了。
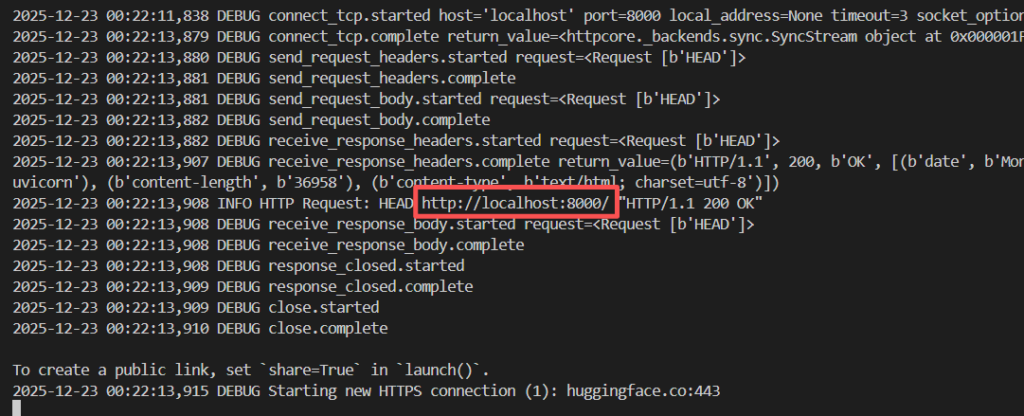
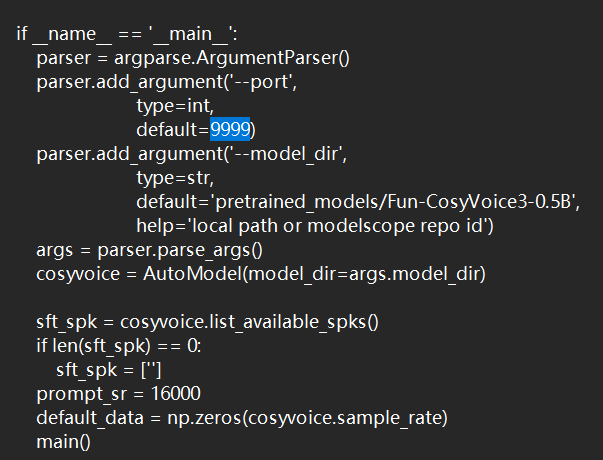
如果没有出现localhost:8000而是存在以下问题,那就是8000这个端口被占用了。
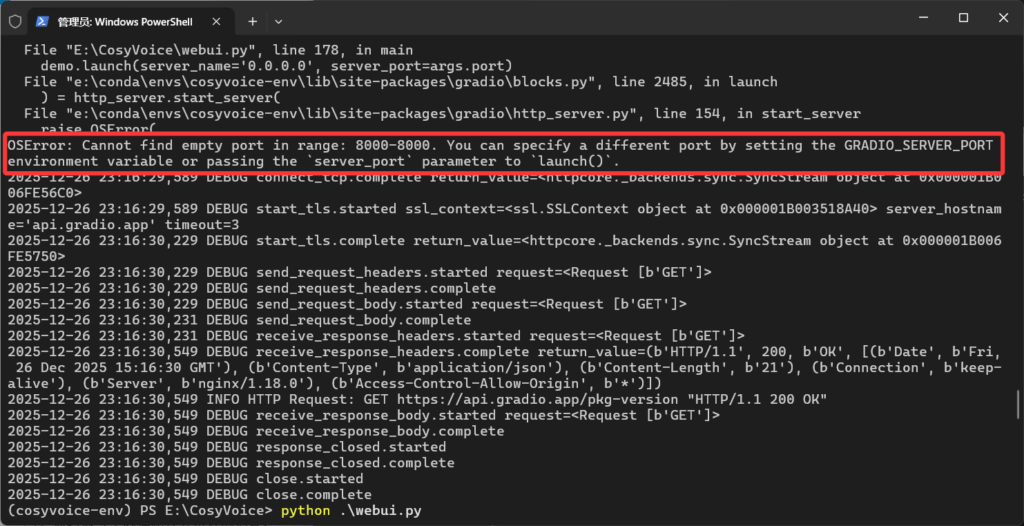
这时候我们只用打开webui.py滑到最底下修改端口为其他就行了
3. 推理与测试
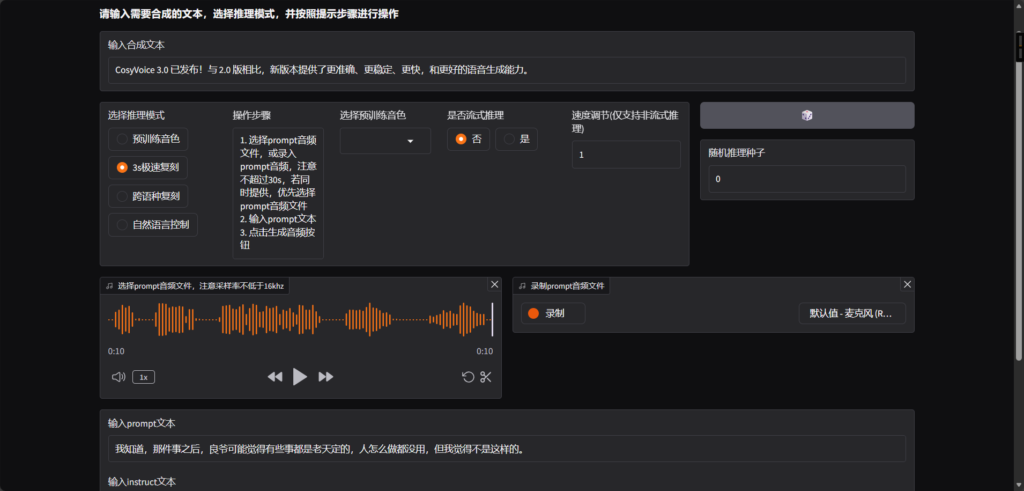
打开网址后会呈现以下界面,其中预训练音色依然为空,我们能够直接使用的推理模式有3s极速复刻、跨语种复刻和自然语言控制。本篇会逐个测试三种功能,以及增加更多的测试音频。
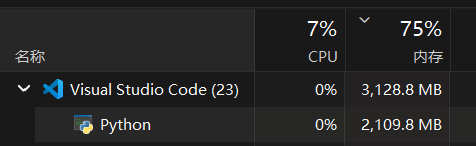
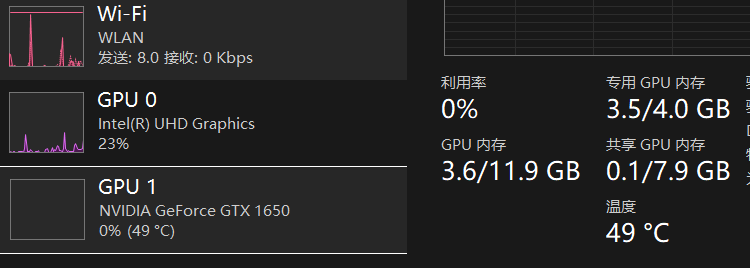
测试机依然为可怜的 GTX1650-4GB显卡,打开任务管理器可以发现,进程用了2.5GB运存用于加载模型,其余的部分填入显存中
以《饿殍·明末千里行》中满穗配音、《绝区零》各角色配音为基准进行各项测试,测试结果如下:
3.1 3s急速复刻:
原声1(满穗 - 女):
我知道,那件事之后,良爷可能觉得有些事都是老天定的,人怎么做都没用,但我觉得不是这样的。
推理1,耗时:72s(直出)
CosyVoice 3.0 已发布!与 2.0 版相比,新版本提供了更准确、更稳定、更快和更好的语音生成能力。
CosyVoice2对比:CosyVoice 2.0 已发布!与 1.0 版相比,新版本提供了更准确、更稳定、更快和更好的语音生成能力。
原声2(满穗 -女):
良爷…你之前,去过洛阳吗?
推理2,耗时24s(直出)
湖边留着一双鞋。鞋是浅蓝色的,鞋头尖尖的,两侧上绣着亮银色的牡丹,看起来精致而小巧,像是收紧羽翼的两只小青鸟
原声3(安比 - 女):
我在听插曲,电影里,一般不会有那么长的空镜头
推理3,耗时44s(直出)
从不谈起自己的故事,仿佛没有过去,是个谜一般的少女。性格沉着冷静,战斗风格异常干练高效,像是经历过常年的训练。
CosyVoice2对比:
原声4(莱卡恩 - 男):
愿您宽恕这份罪孽,赞颂这份忠诚。
推理4.1,耗时16s(直出)
优秀的执事,在任何情况下都能保持风度。
推理4.2,耗时17s(直出)
抱歉,即使如此,我也是不会手下留情的。毕竟,空洞可不是什么需要公平对决的地方。
原声5 (赛斯 - 男)
我知道你没有对我虚情假意,是在和我这个人交朋友,这才是重要的事
推理5,耗时10秒
总有一天,我会成为最厉害的治安官,让那家伙收回之前的话!
原声6(派派!)
要载你一程嘛?记得系好安全带哟
推理6,耗时100s(存在胡言乱语,第3秒后正常)
如果是为了你,这个人稍微努力一下下,也可以哦~
3.2 跨语种复刻
原声1 (莱卡恩 - 日)
ご主人様の願いこそわが無償の使命です。(译:主人的愿望正是我的无偿使命。)
推理1,耗时24s(存在胡言乱语,第3秒后正常)
登山作为一项古老的极限运动,自古以来就吸引了无数冒险者,即使在现代,依然是许多人的热爱。
原声2(爱丽丝 - 日)
タイムフィールドキャリー、アリスがご挨拶するのだわ。(可能有误)
推理2,耗时24s(存在胡言乱语,第3秒后正常)
她无法拒绝完美的对称。
对称之中,存在着秩序与规律。
若看不到对称,她的兔耳和尾巴将会丧失柔顺与光泽,仿佛美好的事物下一秒就会离她而去。
3.3 总结一下:
1. 生成的结果与参考语音有很大的关系,不可能一次性就生成令自己满意的音频,需要不断调整参考音频又或是webui中的🎲随机推理种子。
2. 推理1和推理3使用的参考音频与先前CosyVoice2一致,很明显的特点就是生成的音色与参考音频音色更加相近,cv2那种听座机听筒的沉闷效果在cv3中优化了,生成的音频更加清晰。但是对于语音的断句和停顿在这块就有点稍逊于cv2了,我还是非常喜欢cv2的停顿,恰到好处。
3. 在所有的推理中,推理4莱卡恩推理效果的音色和语气是最接近原声的,两条音频都是使用同一个参考音频生成,似乎是男声的训练素材更多所导向的?
4. 推理5和推理6,以及跨语种复刻都存在胡言乱语或前三秒不可用的情况,推理5没有放上来是因为重试了多次生成语音,甚至生成语音中会出现不属于当前参考音频中的声音(派派的部分参考语音),疑似爆显存的情况,重新加载了几次模型才得到能听的音频。因此在推理6中放了胡言乱语的片段,后续生成的效果就很不错。这种问题对于视频制作者来说问题不大。
胡言乱语的情况由于测试设备硬件性能实在有限,此处不做过多评价,还请高性能显卡的朋友测试一下是否同样出现一样的问题!
4.可能遇到的问题
4.1 在使用“跨语种复刻”时:AttributeError: 'CosyVoice3' object has no attribute 'instruct'
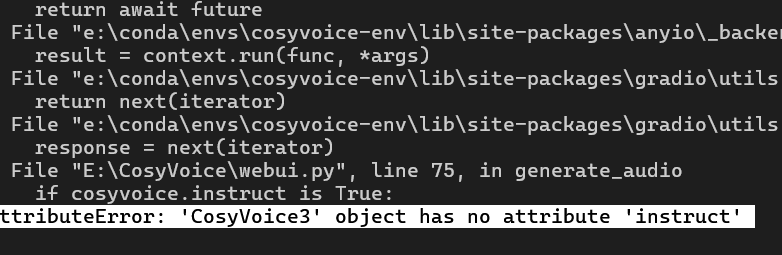
这个问题很有可能是官方疏忽,查看源代码可以发现,这个cosyvoice对象是通过AutoModel判断模型目录下的配置文件确定模型版本的。而且CosyVoice3对象继承于CosyVoice2,而CosyVoice2继承于CosyVoice1,这里面无论如何应该要有一个instruct属性吧,但是找了半天根本没发现有。
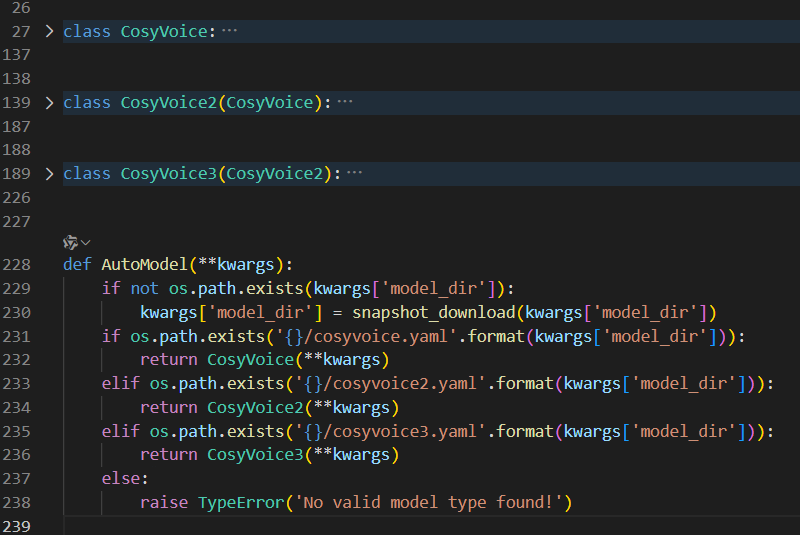
解决办法非常简单暴力,直接注释掉这部分的检查就行,下方的自然语言控制也是如此。
完成后保存重启项目(注意cosyvoice库的引用顺序!!可能会被编辑器自动排序)
5. CosyVoice推理/微调库解析
在之前cosyvoice2中,没有仔细的分析这个位于github上的推理库,现在仔细一看可以发现有很多有意思且实用的封装。
5.1 微调与训练示例
首先是这个examples文件夹,提供了grpo、libritts、magicdata-read三个示例。CosyVoice作为一个完整的语音合成系统,这三个项目展示了在不同数据集、不同训练策略(监督学习、强化学习、偏好学习)下的应用能力。
作为普通用户可能用不上,但可以稍微讲解下方面让感兴趣的读者了解。
5.1.1 GRPO强化学习示例
项目展示了如何通过 veRL 框架使用 GRPO(Group Relative Policy Optimization)强化学习算法 对CosyVoice2大语言模型进行微调。
GRPO最先由DeepseekMath提出的一种策略优化算法(GRPO:Group Relative Policy Optimization - 知乎),显著减少了内存和计算资源的消耗。
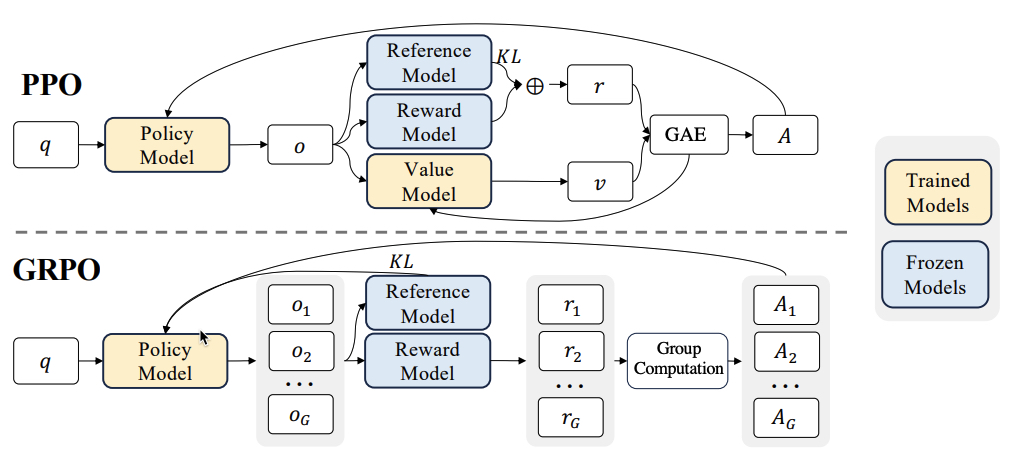
Cosyvoice通过自定义奖励函数(位于token2wav_asr_server.py文件,基于SenseVoice ASR的字符错误率)优化模型,将字符错误率从4.08%降低到3.36%。
5.1.2 LibriTTS英文数据集训练示例 & MagicData-Read中文语音示例
该示例项目实现了在 LibriTTS英语语音数据集 和 MagicData-Read中文语音数据集 上训练(微调)不同版本的CosyVoice模型。
其中包含了三个子版本:
- cosyvoice/: 第一代CosyVoice-300M模型的完整训练流程
- cosyvoice2/: 第二代CosyVoice2-0.5B模型,支持DPO(Direct Preference Optimization)训练
- cosyvoice3/: 最新版CosyVoice3模型,使用DiT(Diffusion Transformer)架构
主要流程为:
- 数据下载与预处理
- 说话人嵌入提取(CamPlus)
- 语音离散token提取
- Parquet格式数据准备
- 分布式训练(LLM/Flow/HiFiGAN组件)
- 模型平均与导出(JIT/ONNX)
5.2 模型部署
第二个就是runtime文件夹,可以发现python文件夹内有用FastAPI实现的Restful架构风格(HTTP-JSON),以及高性能的gRPC架构(HTTP2-Protobuf)。而triton_trtllm则是 Triton + TensorRT 实现的生产级部署框架。以此实现了轻量级部署和高性能生产的各种需求。
5.2.1 Python原生部署方案 (runtime/python/)
框架和技术栈:
- FastAPI: 提供RESTful HTTP API服务
- gRPC: 提供高性能RPC调用接口
- Docker: 容器化部署支持
提供的接口方法:
FastAPI接口 (端口50000):
GET/POST /inference_sft: 监督语音合成 (文本+说话人ID)GET/POST /inference_zero_shot: 零样本语音合成 (文本+提示文本+提示音频)GET/POST /inference_cross_lingual: 跨语言语音合成 (文本+提示音频)GET/POST /inference_instruct: 指令式语音合成 (文本+说话人ID+指令文本)GET/POST /inference_instruct2: 指令式语音合成v2 (文本+指令文本+提示音频)
gRPC接口:
- 使用Protocol Buffers定义服务协议
- 支持流式响应,实时返回音频数据
- 四种请求类型:sft、zero_shot、cross_lingual、instruct
5.2.2 高性能Triton TRTLLM部署方案 (runtime/triton_trtllm/)
框架和技术栈:
- NVIDIA Triton Inference Server: 推理服务器
- TensorRT-LLM: GPU加速的大语言模型推理引擎
- Docker Compose: 容器编排部署
- OpenAI兼容API: 标准化接口
核心特性:
- 流式推理: 支持实时语音合成,首延迟约190ms
- 批量处理: 支持动态批处理,提升吞吐量
- 多模型服务: 同时服务多个模型组件
cosyvoice2: 主LLM模型cosyvoice2_dit: DiT版本模型audio_tokenizer: 音频tokenizerspeaker_embedding: 说话人嵌入提取token2wav: token转音频tensorrt_llm: TensorRT优化的LLM
接口方式:
HTTP REST API:
POST /v2/models/{model_name}/infer支持输入参数:
reference_wav: 参考音频reference_wav_len: 音频长度reference_text: 参考文本target_text: 目标合成文本
6. TUI & 音色保存
(脚本研发中,当前遇到问题是使用存储的音色进行推理,输出的音频完全静音)

发表回复